
Page 100 - 《软件学报》2021年第9期
P. 100
2724 Journal of Software 软件学报 Vol.32, No.9, September 2021
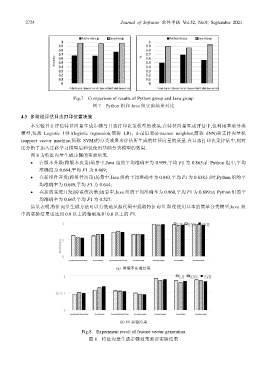
Fig.7 Comparison of results of Python group and Java group
图 7 Python 组和 Java 组实验结果对比
4.3 多阶段评估日志打印位置决策
本实验旨在评估特征向量生成步骤与日志打印决策模型的效果.在特征向量生成评估中,仅利用基础分类
模型,包括 Logistic 回归(logistic regression,简称 LR)、k-最近邻(k-nearest neighbor,简称 kNN)和支持向量机
(support vector machine,简称 SVM)的分类效果来评估所生成的特征向量的质量.在日志打印决策评估中,则对
比分析了加入迁移学习模型后和仅使用基础分类模型的效果.
图 8 为特征向量生成步骤的实验结果.
• 在版本升级(跨版本决策)场景中,Java 组的平均准确率为 0.959,平均 F1 为 0.865;在 Python 组中,平均
准确度为 0.664,平均 F1 为 0.469;
• 在新组件开发(跨组件决策)场景中,Java 组的平均准确率为 0.943,平均 F1 为 0.838;同时,Python 组的平
均准确率为 0.649,平均 F1 为 0.644;
• 在新的系统开发(跨系统决策)场景中,Java 组的平均准确率为 0.960,平均 F1 为 0.899;而 Python 组的平
均准确率为 0.667,平均 F1 为 0.527.
结果表明,特征向量生成方法可以有效地从源代码中提取特征向量.即使使用基本的简单分类模型,Java 组
中的实验结果也达到 0.9 以上的精确度和 0.8 以上的 F1.
(a) 准确率实验结果
(b) F1 实验结果
Fig.8 Experiment result of feature vector generation
图 8 特征向量生成步骤效果验证实验结果