
Page 333 - 《软件学报》2021年第9期
P. 333
田卓 等:神威太湖之光上分子动力学模拟的性能优化 2957
由此可见:对转置后的 4 个向量进行向量化求和后再开平方,得到的向量的 4 个分量分别表示 4 个粒子与 a
粒子的欧几里得距离.由此可见:向量化的 SIMD 指令等价于一个 4 次循环操作,减少了指令数,降低了对指令访
问带宽的要求,而且减少了循环引起的控制相关,提升了访存凝聚性,提高了效率.
3 实验结果
3.1 单节点性能
我们的实例是基于硅结晶的模拟,实验设计上,我们逐步对比了不同的优化方法对性能的影响,以及不同问
题规模下性能的差异.在这一部分,我们主要阐述了在第 2 节中所提出的 3 种优化技术对性能的提升效果.为了
说明可扩展性,我们测试了两种不同的问题规模,分别是 4 096 个粒子和 32 768 个粒子.我们的测试是运行在单
节点上,启用 4 个核组.表 1 给出了神威的系统配置.
Table 1 Sunway TaihuLight supercomputer system configuration
表 1 神威太湖之光超级计算机的系统配置
处理器 SW26010 处理器
指令集 神威 64 位指令集
节点处理器 256CPEs 4MPEs
内存 每个 CG,8GB DDR3
编译语言 C 语言
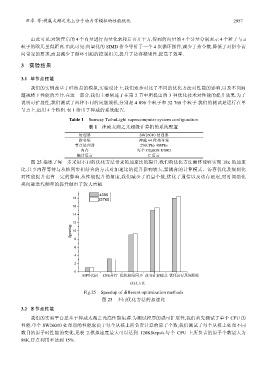
图 25 描述了每一步采用不同的优化方法带来的加速比的提升,我们的优化方法最终能够实现 18x 的加速
比.共享内存等待与从核同步相结合的方式对加速比的提升影响较大,紧耦合的计算模式、访存优化及规则化
对性能提升也有一定的影响.从性能提升的角度,我们减少了消息个数,优化了通信以及访存延迟,对时间演化
类问题迭代频率的提升做出了较大贡献.
4096
18 32768
16
14
12
Speedup 10
8
6
4
2
0
MPE代码 CPE并行 优化核间同步 改变计算模式 优化访存及规则化
优化方法
Fig.25 Speedup of different optimization methods
图 25 不同优化方法的加速比
3.2 多节点性能
我们的实验平台是基于神威太湖之光高性能集群.为测试程序的强可扩展性,我们首先测试了单个 CPU 的
性能.单个 SW26010 处理器的性能取决于每个从核上所负责计算的原子个数,我们测试了每个从核上处理不同
数目的原子时性能的变化,见表 2.模拟速度最大可以达到 120KSteps/s.每个 CPU 上所负责的原子个数最大为
98K,浮点利用率达到 15%.