
Page 32 - 《软件学报》2021年第6期
P. 32
1606 Journal of Software 软件学报 Vol.32, No.6, June 2021
息,故准确率在这里也有一定的参考价值.因此,综合考虑后,我们会更加关心模型在 F1 维度上的表现.
4 实验结果
本节将给出实验的结果,并对实验结果进行分析.为避免实验结果的偶然性,我们进行了十折交叉实验,本
节中的数据均为交叉实验的平均结果.
4.1 调参实验
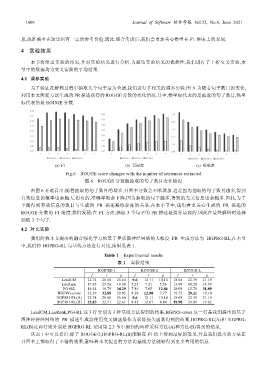
为了验证在解码过程中抽取几个句子最为合适,我们进行了相关的调参实验.图 6 为随着句子数目的变化,
利用本文所提方法生成的 PR 描述获得的 ROUGE 分数的变化情况.其中,横坐标代表的是抽取的句子数目,纵坐
标代表的是 ROUGE 分数.
(a) F1 (b) 召回率 (c) 准确率
Fig.6 ROUGE score changes with the number of sentences extracted
图 6 ROUGE 分数随抽取的句子数目变化情况
由图 6 不难看出:随着抽取的句子数目的增多,召回率分数会不断增加.这是因为抽取的句子数目越多,得到
有效信息的概率也会越大.相对的,准确率则会下降,因为抽取的句子越多,得到的无关信息也会越多.因此,为了
平衡得到有效信息的数目与生成的 PR 描述凝练程度的关系,在本小节中,我们着重关心生成的 PR 描述的
ROUGE 分数的 F1 维度.我们发现:在 F1 方面,抽取 3 个句子的 PR 描述是得分最高的.因此在最终解码时选择
抽取 3 个句子.
4.2 对比实验
我们简称本文提出的融合强化学习的基于异质图神经网络的大粒度 PR 生成方法为 HGPRG-RL,在本节
中,我们将 HGPRG-RL 与基线方法进行对比,结果见表 1.
Table 1 Experimental results
表 1 实验结果
ROUGE-1 ROUGE-2 ROUGE-L
f r p f r p f r p
LeadCM 22.74 26.68 26.64 9.6 12.11 10.14 18.68 22.39 21.19
LexRank 17.85 23.26 19.50 5.23 7.21 5.36 13.89 18.58 14.99
PG+RL 19.34 16.79 34.29 7.86 7.05 12.84 18.08 15.76 31.89
HGPRG-cross 22.59 32.88 22.05 8.38 12.90 7.77 19.75 29.21 19.10
HGPRG-RL(A) 22.74 26.68 26.64 9.6 12.11 10.14 18.68 22.39 21.19
HGPRG-RL(B) 22.83 32.51 22.61 8.45 12.67 8.44 19.98 28.89 19.62
LeadCM,LaxRank,PG+RL 这 3 行分别为 3 种基线方法得到的结果,HGPRS-cross 这一行是我们提出的基于
图神经神经网络的 PR 描述生成器使用交叉熵函数作为训练损失函数得到的结果,HGPRG-RL(A)和 HGPRG-
RL(B)这两行则分别是 HGPRG-RL 使用第 2.3 节中提到的两种采样方法(A)和方法(B)得到的结果.
从表 1 中可以看出:除了 ROUGE-2,HGPRG-RL(B)能够在 F1 值上得到最好的效果,并且我们提出的方法在
召回率上都取得了不错的效果,意味着本文提出的方法比基线方法能够得到更多有用的信息.