
Page 173 - 《软件学报》2020年第11期
P. 173
刘井莲 等:一种基于模糊相似关系的局部社区发现方法 3489
在 Karate 数据集上,本文算法和 CNWNN 算法的 Precision 指标最高,Recall 指标低一点,CNWNN 算法的
F-score 指标最高,本文算法次之.在 Football 数据集上,本文算法的 Precision 和 Recall 都高于其他 5 种算法,因
此,F-score 明显高于其他 5 种算法.在 Polbooks 数据集上,本文算法的 Recall 指标最高,虽然 Precision 略低于
Clause、GMAC、FlowPro、CNWNN 算法,但 F-score 指标明显高于其他 5 种算法.在 DBLP 数据集上,本文算
法的 Precision、Recall、F-score 都高于 Clauset 和 CNWNN 算法.与在仿真网络数据集上的结果相同,基于模糊
相似关系的局部社区发现算法选择邻居节点的方法优于其他算法.
综合以上分析可以得出,在这 4 个真实网络数据集上,本文算法表现最好.
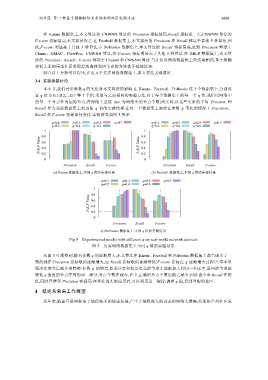
3.4 实验参数讨论
本小节,我们讨论参数 q 的变化对本文算法的影响.在 Karate、Football、Polbooks 这 3 个数据集上,分别设
置 q 值为 0.1,0.2,...,0.7 等 7 个值.采取与之前相同的实验方法,对于每个数据集上的每一个 q 值,我们以网络中
的每一个节点作为起始节点,在网络上重复 n(n 为网络中的节点个数)次实验,以这些实验的平均 Precison 和
Recall 作为当前数据集上的当前 q 值的实验结果.在每一个数据集上观察在参数 q 变化的情况下,Precision、
Recall 和 F-score 指标如何变化.实验结果如图 5 所示.
q=0.1 q=0.3 q=0.5 q=0.7 q=0.1 q=0.3 q=0.5 q=0.7
q=0.2 q=0.4 q=0.6 q=0.2 q=0.4 q=0.6
1 1
0.8 0.8
P-R-F Value 0.6 P-R-F Value 0.6
0.4
0.4
0.2
0
0 0.2
Precision Recall F-score Precision Recall F-score
(a) Karate 数据集上,不同 q 值的实验结果 (b) Football 数据集上,不同 q 值的实验结果
q=0.1 q=0.3 q=0.5 q=0.7
q=0.2 q=0.4 q=0.6
1
0.8
P-R-F Value 0.6
0.4
0.2
0
Precision Recall F-score
(c) Polbooks 数据集上,不同 q 值的实验结果
Fig.5 Experimental results with different q on real-world network datasets
图 5 真实网络数据集上不同 q 值的实验结果
从图 5 可观察到,随着参数 q 的逐渐增大,本文算法在 Karate、Football 和 Polbooks 数据集上都呈现出了一
致的规律:Precision 指标取值逐渐增大,而 Recall 指标取值逐渐降低;F-score 指标在 q 逐渐增大过程中,基本呈
现出先增大后减少的趋势.参数 q 的增大,要求只有相似度更高的节点才能被加入到同一社区中,返回的节点是
较低 q 值返回节点序列的前一部分,节点个数在减少,其中,正确的节点个数也随之减少,因此查全率 Recall 在降
低,同时查准率 Precision 在提高.在算法的实际应用时,可以利用这一规律,调整 q 值,得到理想的社区.
4 结论与未来工作展望
近年来,随着互联网和电子通信技术的快速发展,产生了规模庞大的动态的网络大数据,传统的全局社区发