
Page 217 - 《爆炸与冲击》2026年第5期
P. 217
第 46 卷 赵春风,等: 基于XGBoost的PC板爆炸损伤评估模型 第 5 期
′
f (x) ∼ N(µ(x),k(x, x )) (6)
式中:f(x) 为高斯过程,N 为高斯过程的正态分布函数,μ(x) 为均值函数,k(x,x′) 为协方差函数。
y Observation Dataset
Mean prediction
Confidence interval
. . .
Decision tree-1 Decision tree-2 Decision tree-N
Result-1 Result-2 Result-N
95% confidence level Majority voting/averaging
O x Final result
Dataset X
Tree 1{X,θ 1 } Tree 2{X,θ 2 } Tree k{X,θ k }
Node splitting by
objective function
… … …
…
Residual Residual.. Residual
f 1 {X,θ 1 } f 2 {X,θ 2 } … f k−1 {X,θ k−1 } f k {X,θ k }
Σf k {X,θ k }
(c) XGBoost
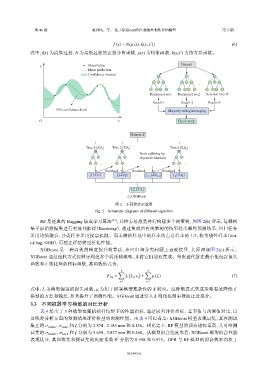
图 2 不同算法示意图
Fig. 2 Schematic diagrams of different algorithm
RF 是经典的 Bagging 集成学习算法 [24] ,其核心思想是并行构建多个决策树,如图 2(b) 所示,每棵树
基于原始数据集进行有放回抽样(Bootstrap),通过集成所有决策树的结果得出最终预测结果,回归任务
采用均值融合,分类任务采用投票机制。而未被抽样选中的样本约占总样本的 1/3,称为袋外样本(out-
of-bag,OOB),可独立评估模型泛化性能。
XGBoost 是一种高效的梯度提升树算法,在回归和分类问题上表现优异,其原理如图 2(c) 所示。
XGBoost 通过迭代方式按顺序构建多个弱预测模型,并将它们加权集成。每次迭代旨在最小化包含损失
函数和正则化项的目标函数,其函数形式为:
n k
∑ ( ) ∑
F obj = L ˆy j ,y j + µ( f t ) (7)
j=1 t=1
式中:L 为模型偏置的损失函数,μ 为用于抑制模型复杂性的正则项。这种渐进式集成策略有效降低了
模型的方差和偏差,显著提升了预测性能。XGBoost 通过引入正则化机制有效防止过拟合。
3.3 不同机器学习模型的对比分析
表 4 给出了 3 种模型在随机抽样情形下的性能指标,通过回归评价指标、真实值与预测值对比,以
及残差分析方面的预测结果评价模型的预测性能。由表 4 可以看出:XGBoost 模型表现最优,其在测试
集上的 σ 、σ E 和 ξ 分别为 2.874、2.185 mm 和 0.136。相比之下,RF 模型的误差指标最高,其对应测
RMSE MA
试集的 σ RMSE 、σ MA E 和 ξ 分别为 5.659、3.837 mm 和 0.268。从模型拟合优度来看,XGBoost 模型拟合性能
表现优异,其训练集和测试集的决定系数 R 分别为 0.998 和 0.975。GPR 与 RF 模型的拟合效果均次于
2
051443-6