
Page 195 - 《软件学报》2020年第9期
P. 195
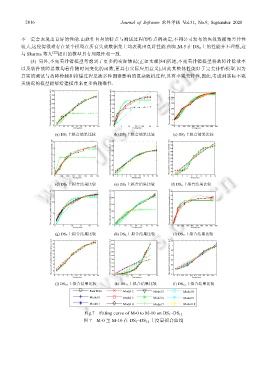
2816 Journal of Software 软件学报 Vol.31, No.9, September 2020
不一定会表现出良好的性能.由软件自身的特点与测试过程的特点所决定,不同公司发布的失效数据集差异性
较大,这使得很难存在某个模型在所有失效数据集上均表现出良好性能.例如,M-5 在 DS 2 上的性能并不理想,这
与 Sharma 等人 [22] 提出的模型具有局限性相一致.
(3) 另外,不完美排错模型考虑到了更多的实际情况(正如文献[84]所述,不完美排错模型将故障排除效率
以及软件故障总数均看作随时间变化的函数,更具有实际应用意义),因此其整体性能好于完美排错模型.因为
真实的测试与故障检测和排错过程是被多种因素影响的复杂随机过程,具有不完美特性,因此,考虑到实际不完
美情况的模型能够给建模带来更多的精准性.
(a) DS 1 上拟合结果比较 (b) DS 2 上拟合结果比较 (c) DS 3 上拟合结果比较
(d) DS 4 上拟合结果比较 (e) DS 5 上拟合结果比较 (f) DS 6 上拟合结果比较
(g) DS 7 上拟合结果比较 (h) DS 8 上拟合结果比较 (i) DS 9 上拟合结果比较
(j) DS 10 上拟合结果比较 (k) DS 11 上拟合结果比较 (l) DS 12 上拟合结果比较
Raw Data Model 2 Model 5 Model 8
Model 0 Model 3 Model 6 Model 9
Model 1 Model 4 Model 7 Model 10
Fig.7 Fitting curve of M-0 to M-10 on DS 1 ~DS 12
图 7 M-0 至 M-10 在 DS 1 ~DS 12 上度量拟合曲线