
Page 39 - 《软件学报》2020年第10期
P. 39
徐梦炜 等:面向移动终端智能的自治学习系统 3015
我们同时验证了数据增强技术对模型准确率的影响.对于 LSTM 模型,我们使用同义词替换技术;对于
MobileNet 模型,我们使用裁剪、旋转和移位技术.需要注意的是,两种技术都可以将训练数据量提升最高超过 5
倍,为了平衡训练的计算开销,本文所做实验都只在生成数据中采样不超过原数据量的 1 倍.实验结果表明,数据
增强对词预测和图像分类两种任务分别有 0.9%和 3.1%的准确率提升.后者的效果更明显:事实上,自然语言处
理中的数据增强比起图片数据而言确实更加困难.
此外,我们还通过实验探究了在线学习对模型准确率的提升效果.从预训练的模型出发,然后将数据集序列
化,不断地输入到 AutLearn 系统中.对于每一条数据,AutLearn 会首先做出预测,然后利用该数据进行模型的强
化训练,不断重复该过程,最后汇总预测的整体结果.这个过程即是模拟用户在使用该模型的过程中 AutLearn 对
用户当前行为(产生数据)做出的适应性改变.我们发现,对于 LSTM 和 MobileNet 模型而言,相比只用预训练模型
预测所有数据,在线学习可以在所有数据上平均提升 5.9%和 3.1%的模型准确率.并且,该提升在后面输入的数
据上更加明显,原因是随着更多数据的输入,模型得到了持续的学习,精度上升.实验结果表明,在线学习可以有
效地根据用户行为改变(如输入模式)适应性地对模型进行调整,以达到更高的准确率.
4.3 终端训练开销
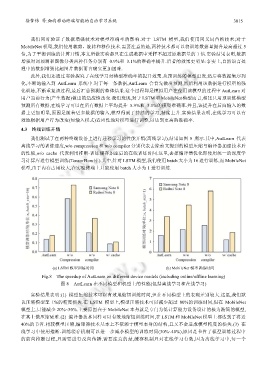
我们测试了在两种终端设备上进行迁移学习的性能开销(离线学习),结果如图 8 所示.其中,AutLearn 代表
离线学习的训练速度,w/o compression 和 w/o compiler 分别代表去除前文提到的模型压缩与编译器加速技术后
的性能,w/o cache 代表利用推断-训练缓存加速后的在线训练时间.这里,去掉编译器优化即使用统一的深度学
习计算库进行模型训练(TensorFlow 库).其中,针对 LSTM 模型,我们使用 batch 大小为 16 进行训练,而 MobileNet
模型,由于内存占用较大,在实验终端上只能使用 batch 大小为 1 进行训练.
(a) LSTM 模型训练时间 (b) MobileNet 模型训练时间
Fig.8 The speedup of AutLearn on different device models (including online/offline learning)
图 8 AutLearn 在不同模型和机型上的性能(包括离线学习和在线学习)
实验结果表明:(1) 模型压缩技术可以有效地缩短训练时间,但在不同模型上的表现差别较大.这里,我们默
认压缩模型至 1%的精度损失.在 LSTM 模型上,模型压缩技术可以减少超过 80%的训练时间,但在 MobileNet
模型上,只能减少 20%~30%.主要原因在于 MobileNet 本身就是专门为低计算能力设备设计的极为精简的模型,
在其上做压缩更难.(2) 编译器技术同样可以有效地缩短训练时间,在 LSTM 和 MobileNet 模型上都达到了将近
40%的节省.相较模型压缩,编译器技术基本上不依赖于模型本身的结构,且又不会造成模型精度的损失.(3) 在
线学习中使用推断-训练缓存机制可以进一步减小模型的训练时间(30%~40%),原因是节省了模型训练过程中
的前向推断过程,只需要进行反向传播.需要注意的是,缓存机制只对在线学习有效,因为离线学习中,每一个