
Page 306 - 《软件学报》2025年第12期
P. 306
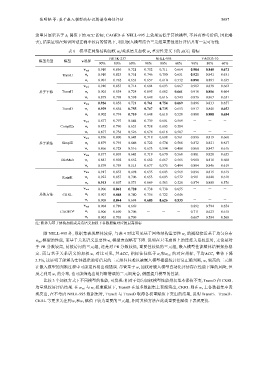
张明韬 等: 基于嵌入模型的知识图谱准确性评估 5687
这里只展示基于 λ 1 阈值下的 ACC 指标; CAGED 在 NELL-995 上效果远低于其他模型, 不具有参考价值, 因此略
去), 结果证明在知识图谱正确率较高的情况下, 利用嵌入模型结合三元组重要性进行评估具有一定可行性.
表 6 模型在网络结构加权 w s /关系语义加权 w r 重要性定义下的 ACC 1 指标
FB15K-237 NELL-995 YAGO3-10
模型类型 模型 w选择
90% 80% 60% 90% 80% 60% 90% 80% 60%
0.910 0.856 0.721 0.752 0.711 0.664 0.904 0.840 0.671
w uni
TransE w s 0.910 0.823 0.751 0.746 0.700 0.651 0.921 0.841 0.631
w r 0.901 0.762 0.653 0.657 0.610 0.512 0.890 0.881 0.635
0.910 0.855 0.714 0.694 0.693 0.667 0.902 0.839 0.662
w uni
基于平移 TransH w s 0.903 0.854 0.724 0.695 0.682 0.661 0.918 0.856 0.664
0.879 0.798 0.598 0.648 0.616 0.543 0.876 0.867 0.651
w r
0.926 0.856 0.721 0.761 0.754 0.669 0.896 0.833 0.657
w uni
TransD w s 0.929 0.854 0.755 0.747 0.735 0.653 0.917 0.840 0.652
0.902 0.774 0.710 0.648 0.618 0.520 0.888 0.888 0.654
w r
0.877 0.797 0.644 0.739 0.601 0.569 - - -
w uni
ComplEx w s 0.873 0.790 0.653 0.738 0.605 0.584 - - -
0.877 0.738 0.526 0.678 0.618 0.507 - - -
w r
0.876 0.800 0.643 0.718 0.688 0.561 0.896 0.819 0.660
w uni
基于乘法 SimplE w s 0.879 0.793 0.646 0.722 0.574 0.566 0.872 0.821 0.637
0.866 0.728 0.516 0.673 0.594 0.488 0.868 0.847 0.616
w r
0.877 0.803 0.645 0.719 0.670 0.560 0.881 0.820 0.655
w uni
DistMult w s 0.881 0.802 0.652 0.682 0.667 0.565 0.900 0.810 0.668
w r 0.879 0.759 0.515 0.677 0.575 0.494 0.884 0.846 0.619
w uni 0.917 0.853 0.698 0.635 0.603 0.569 0.896 0.815 0.619
RotatE w s 0.922 0.857 0.706 0.653 0.603 0.572 0.901 0.840 0.610
0.913 0.807 0.573 0.669 0.583 0.528 0.874 0.888 0.576
w r
w uni 0.906 0.861 0.728 0.738 0.738 0.655 - - -
其他方法 CKRL w s 0.907 0.868 0.740 0.736 0.722 0.646 - - -
w r 0.909 0.844 0.694 0.685 0.626 0.533 - - -
w uni 0.904 0.789 0.669 - - - 0.892 0.794 0.654
CAGED* w s 0.906 0.690 0.706 - - - 0.711 0.623 0.618
w r 0.903 0.703 0.709 - - - 0.667 0.584 0.568
注: 粗体为基于结构加权或关系语义加权下各数据集对应的最高指标
除 NELL-995 外, 数据集表现整体较好, 与表 4 对比可见基于网络结构重要性 w s 的模型接近基于均匀分布
w r 模型表现略有下降. 说明在只考虑图上的连接关系权重时, 无论是对
w uni 模型的性能, 而基于关系语义重要性
于 PR 分数较高, 易被访问的三元组, 还是对 PR 分数较低, 重要性较低的三元组, 嵌入模型性能整体结果保持稳
定. 而与基于关系语义的加权 w r 对比可见, 其 ACC 1 指标往往低于 w s 和w uni 的对应指标, 平均 ACC 1 整体下降
5.3%, 这证明了能够为实体提供独特信息的三元组往往难以被嵌入模型根据统计信息正确判断, w r 较高的三元组
在嵌入模型的判断过程中可能更容易出现错误. 尽管基于 w r 加权时嵌入模型自动化评估存在性能下降的风险, 但
反之利用 w r 的分布, 也可能筛选出易判断错误的三元组集合, 侧面提升模型的性能.
比较 3 个加权方式下不同模型的性能, 可发现: 相对于均匀加权模型性能排名基本保持不变, TransD 和 CKRL
均呈现较好评估结果. 在 w uni 与 w s 权重赋值下, TransD 在最多数据集上表现突出, CKRL 则在 w r 上各数据集中表
现突出, 在不考虑 NELL-995 数据集时, TransE 与 TransD 取得各权重赋值下突出的结果, 说明 TransE、TransD、
CKRL 等更多关注到 w s 和w r 赋值下较为重要的三元组, 相对其他方法在此类重要性赋值下表现更优.