
Page 302 - 《软件学报》2025年第12期
P. 302
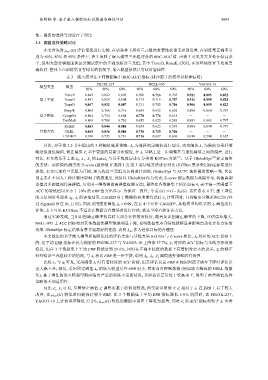
张明韬 等: 基于嵌入模型的知识图谱准确性评估 5683
性、阈值的选择等均进行了对比.
3.3 阈值选择策略对比
µ uni (G) 评估情况进行实验, 在该条件下所有三元组的重要性权重无差别设置. 在训练集正确率分
本文首先对
别为 60%, 80% 和 90% 条件下, 表 3 反映了嵌入模型三元组评分的 ROC-AUC 值. 由表 3 可见其大多处在较高水
平, 说明大部分模型能够区分测试集中的正确或错误三元组, 其中 TransD, RotatE, CKRL 在该环境设置下效果普
遍较好. 整体上在训练集含有错误的情况下, 嵌入模型依然具有较好鲁棒性.
表 3 嵌入模型在不同数据集中 ROC-AUC 指标 (排序前 3 的模型以粗体标明)
FB15K-237 NELL-995 YAGO3-10
模型类型 模型
90% 80% 60% 90% 80% 60% 90% 80% 60%
TransE 0.842 0.822 0.805 0.700 0.716 0.705 0.921 0.885 0.832
基于平移 TransH 0.841 0.824 0.804 0.713 0.715 0.707 0.911 0.888 0.824
TransD 0.847 0.832 0.807 0.711 0.702 0.706 0.906 0.889 0.823
SimplE 0.804 0.766 0.716 0.683 0.632 0.602 0.888 0.860 0.797
基于乘法 ComplEx 0.804 0.754 0.684 0.778 0.776 0.618 - - -
DistMult 0.800 0.768 0.726 0.655 0.625 0.583 0.881 0.863 0.797
RotatE 0.863 0.844 0.806 0.654 0.625 0.593 0.904 0.874 0.797
其他方法 CKRL 0.845 0.834 0.806 0.730 0.729 0.706 - - -
CAGED 0.740 0.735 0.731 0.716 0.697 0.696 0.614 0.584 0.625
其次, 对于第 2.2 节中提出的 3 种阈值选择策略: λ 0 为选择固定阈值进行划分, 动态阈值 λ 1 为借助负采样策
′ λ 1 基础上进一步调整其与最优阈值之间的偏差, 进行
略近似最优阈值, 修正阈值 λ 基于更强的高斯分布假设, 在
1
′ Label λ 与基于线性层进行分类的 KGTtm 方法 [9] 、基于 GlobalOpt [17] 标定阈值
对比. 本文将基于上述 λ 0 , λ 1 , λ 的
1
的方法、离群值检测方法 Z-score (超参数 K 选择 1.5) 这 3 类基线方法进行对比 (KGTtm 要求采用标注标签进行
训练, 本文以现有三元组为正例, 加入构造三元组为负例进行训练; GlobalOpt 与 ACTC 选择阈值策略一致, 其区
别主要在不同人工标注顺序影响了收敛速度, 此处以 GlobalOpt 作为代表; Z-score 假定数据为高斯分布, 将偏离期
望值过多的值视作离群值, 为常用一维数据的离群值检测方法), 最终在各数据集上结果如表 4, 表中每一类阈值下
ACC 的最优值以及小于 10% 的 ERR 值突出显示. 为保证一致性, 令 S 1 (G) := G −S 2 (G). 需注意表 4 中, 基于乘法
的方法同时考虑其 λ 0 , λ 1 的评估结果, CAGED 对于数据的要求使得此时 λ 1 计算困难, 且其输出分数范围已知 (经
过 Sigmoid 后在 (0, 1) 间), 因此采用固定阈值 λ 0 = 0.99, 在表 4 中记作 CAGED*, 其他模型均仅采用 λ 1 阈值进行
评估; 表 3 可见 KGClean 不适合在数据含有错误时进行评估, 故这里没有验证该方法.
通过实验发现, 当知识图谱正确率较高时大部分评估效果较好, 随着知识图谱正确率的下降, 评估误差增大,
NELL-995 上 ACC 指标相对其他数据集模型效果明显下降, 说明数据集本身特性能够显著影响自动化评估方法的
效果. GlobalOpt 标定结果有着普遍最好的性能, 说明 λ opt 作为近似目标的合理性.
本文提出的基于嵌入模型和阈值优化的评估方法与基线方法 KGTtm 与 Z-score 相比, λ 0 对应的 ACC 指标下
降, 但平均 ERR 指标在较为稠密的 FB15K-237 与 YAGO3-10 上降低 37.7%, λ 1 对应的 ACC 指标与基线方法效果
接近, 但在 3 ERR 降低达到 29.0%, 同时在正确率较低的数据上有着相对更小的误差, λ 的修正
′
个数据集上平均
1
′
针对错误三元组较多的情况, 与 λ 1 相比 ERR 进一步下降, 说明 λ 0 , λ 1 , λ 阈值选择策略的有效性.
1
比较 λ 1 与 λ 0 可见, 采用阈值 λ 1 时有着较好的 ACC 指标, 但其评估误差 ERR 在知识图谱正确率下降时评估误
ERR 更小, 然而面对特殊数据 (例如较为稀疏的 NELL 数据
差大幅上升; 相反, 采用固定阈值 λ 0 的嵌入模型尽管
集), 基于乘法的嵌入模型可能面临更严重的训练不足的情况, 其评估误差常处于较高水平, 说明了两类阈值选择
策略的不同适用性.
′ ′ ′ ERR 上有了较大
对比 λ , λ 1 可见, 尽管修正阈值 λ 调整所基于的假设较强, 但实验证明修正 λ 相对于 λ 1 在
1
1
1
改善, 在 µ uni (G) 较低时仍能保持较小 ERR. 在 3 个数据集上平均 ERR 指标降低 8.9% 的同时, 在 FB15K-237,
YAGO3-10 上评估误差降低 37.2%, µ uni (G) 较低的数据中误差下降更为显著; 同时 λ 的 ACC 指标相较于 λ 1 也普
′
1