
Page 138 - 《软件学报》2025年第12期
P. 138
荣垂田 等: 多目标深度强化学习驱动的数据库系统参数优化技术 5519
场景.
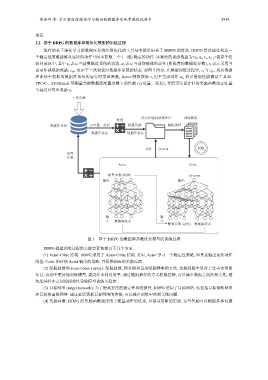
2.2 基于 DDPG 的数据库参数优化模型的训练过程
现有的基于强化学习的数据库系统参数优化的工具基本都采用基于 DDPG 的算法. DDPG 算法通过构造一
个确定性策略能够从连续的动作空间中获取一个 (一组) 确定的动作. 该算法的训练数据为<s t , a t , r t , s t+1 >储存于经
验回放池中, 其中 s t 表示当前数据库系统的状态, a t 表示当前智能体的动作 (即推荐的数据库参数), r t 表示采用当
前动作获取的奖励, s t+ 表示下一次调优时数据库系统的状态. 如图 5 所示, 在模型训练过程中, s t 与 s t+ 均从数据
1
1
库系统中获取的数据库系统的运行时度量参数; Actor 网络获取 s t 用于生成动作 a t ; 然后借助性能测试工具如:
TPC-C、SYSBench 等测量当前数据库配置参数下的性能 (吞吐量、延迟), 并用事先设计好的奖励函数由吞吐量
与延迟计算出奖励 r t .
工作负载
优先经验回放缓冲区 训练数据
处理
数据库系统 吞吐量、延迟 标量奖励 随机抽样
数据库状态 数据库状态
动作 Q-error 训练
设置
参数
Actor Critic
配置参数 (动作) Q-value
...
输出 输出
... ...
... ...
... ...
... ... ...
输 ... 输 ... ...
入 数据库状态 入
配置参数 (动作) 数据库状态
图 5 基于 DDPG 的数据库参数优化模型的训练过程
DDPG 模型训练过程的关键要素包括以下几个方面.
(1) Actor-Critic 结构: DDPG 采用了 Actor-Critic 结构. 其中, Actor 学习一个确定性策略, 即直接输出连续动作
的值. Critic 则评估 Actor 输出的策略, 并提供相应的奖励反馈.
(2) 经验回放池 (experience replay): 经验回放, 即存储和重用经验样本的方法. 这些经验中包含了过去决策的
信息, 有助于更好地训练模型, 提高样本利用效率; 通过随机抽样的方式获取经验, 可以减少数据之间的相关性, 避
免连续样本之间的相关性导致模型训练不稳定.
(3) 目标网络 (target network): 为了提高算法的稳定性和收敛性, DDPG 使用了目标网络. 这包括目标策略网络
和目标值函数网络. 通过延迟更新目标网络的参数, 可以减少训练中的相关性问题.
(4) 奖励函数: DDPG 的奖励函数通常用于衡量动作的优劣, 以指导策略的更新. 这些奖励可以根据具体问题