
Page 140 - 《软件学报》2025年第12期
P. 140
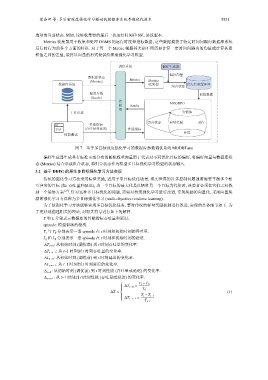
荣垂田 等: 多目标深度强化学习驱动的数据库系统参数优化技术 5521
选项的当前状态. 例如, 垃圾收集器的最后一次运行时间和 SSL 协议版本.
Metrics 收集器用于收集和处理 DBMS 的运行时度量指标数据, 这些数据捕获了特定时间间隔内数据库系统
运行时行为的各个方面的特征. 对于每一个 Metric 根据其类别不同需要计算一定时间间隔内的均值或计算其累
积值之间的差值, 最终以向量的形式提供给深度强化学习模型.
调优系统 偏好生成器
偏好向量
数据库状态
Metrics
(Metrics) Metrics
数据库系统 收集器 优先经验缓冲池
组合状态
配置参数 训练数据
(Knobs)
控 MODDPG
制 Knobs
器
工作负载 智能体
组合状态 向量奖励 动作
性能指标
Test (吞吐量和延迟) 性能指标
环境
性能测试
图 7 基于多目标深度强化学习的数据库参数调优系统 MODBTune
偏好生成器生成具有标准正态分布的随机权重向量用于代表对不同优化目标的偏好, 将偏好向量与数据库状
态 (Metrics) 结合形成组合状态, 将组合状态作为模型多目标强化学习模型的状态输入.
3.2 基于 DDPG 的原生多目标强化学习方法实现
传统的强化学习方法采用标量奖励, 适用于单目标优化场景. 现实世界的许多控制问题通常需要平衡多个相
互冲突的目标 (如: 吞吐量和延迟), 当一个目标的最大化是以牺牲另一个目标为代价时, 决策者必须在它们之间找
到一个妥协方案 [25] . 针对这种多目标优化的问题, 需要对传统强化学习进行改进, 实现奖励的向量化. 采用向量奖
励的强化学习方法称为多目标强化学习 (multi-objective reinforce learning).
为了使强化学习方法能够实现多目标优化任务, 要对传统的标量奖励机制进行改进, 实现的具体细节如下. 为
了更好地描述相关的理论, 对相关符号进行如下的解释.
T 和 L 分别表示数据库的性能指标吞吐量和延迟.
episode: 模型训练的轮次.
T t 与 T 0 分别表示一条 episode 在 t 时刻和初始时刻的吞吐量.
L t 和 L 0 分别表示一条 episode 在 t 时刻和初始时刻的延迟.
∆T t→0 : 从初始时刻 (调优前) 到 t 时刻吞吐量的变化率.
∆T t→t−1 : 从 t–1 时刻到 t 时刻吞吐量的变化率.
∆L t→0 : 从初始时刻 (调优前) 到 t 时刻延迟的变化率.
∆L t→t−1 : 从 t–1 时刻到 t 时刻延迟的变化率.
∆ t→0 : 从初始时刻 (调优前) 到 t 时刻性能 (吞吐量或延迟) 的变化率.
∆ t→t−1 : 从 t–1 时刻到 t 时刻性能 (吞吐量或延迟) 的变化率.
T t −T 0
∆T t→0 =
T 0
∆T = (1)
T t −T t−1
∆T t→t−1 =
T t−1