
Page 133 - 《软件学报》2025年第12期
P. 133
5514 软件学报 2025 年第 36 卷第 12 期
一般都有上百个可供调整的参数, 参数之间、参数与数据库性能之间存在着复杂的关系. 数据库系统参数调优的
挑战主要来自以下几个方面.
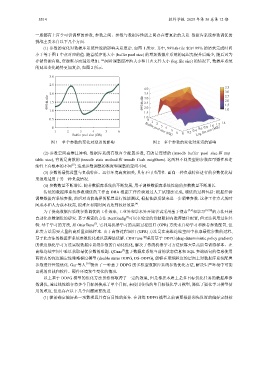
(1) 参数的变化对数据库系统性能的影响关系复杂. 如图 1 所示. 其中, 99%th-tile 表示 99% 的请求完成时间
小于等于图 1 中点对应的值. 随着缓冲池大小 (buffer pool size) 的增加数据库系统的延迟先提升后减少, 随后因为
存储资源有限, 资源耗尽而延迟增加. 当同时调整缓冲池大小和日志文件大小 (log file size) 的情况下, 数据库系统
的延迟变化趋势更加复杂, 如图 2 所示.
3.0
2.5
3.5
4.0
3.0
2.0 3.5 2.5
99%th-tile 1.5 99%th-tile 3.0 2.0
2.5
1.5
1.0 2.0 1.0
1.5
1.0
0.5 0
1 1.4
2 1.2
3 1.0
0 Buffer pool size (GB) 0.6 0.8
4
1 2 3 4 5 6 5 6 0.2 0.4 Log file size (MB)
Buffer pool size (GB) 0
图 1 单个参数的变化对延迟的影响 图 2 多个参数的变化对延迟的影响
(2) 参数空间高维且异构. 数据库系统有数百个配置参数, 有的是连续的 (innodb_buffer_pool_size 和 tmp_
table_size), 有的是离散的 (innodb_stats_method 和 innodb_flush_neighbors). 这两种不同类型的参数在可微性和连
续性上有根本的不同 [3] , 造成参数调整的难度和调整的空间不同.
(3) 参数的最优设置与负载特征、运行环境高度相关, 具有不可重用性. 面向一种负载特征进行的参数优化结
果很难适用于另一种负载情况.
(4) 参数数量不断增长. 随着数据库系统的不断发展, 用于调整数据库系统性能的参数数量不断增长.
传统的数据库系统参数调优的工作由 DBA 根据工作经验通过人工试错法完成, 调优的过程包括: 根据经验
调整数据库系统参数, 然后对当前选择的配置进行性能测试, 根据性能反馈来进一步调整参数. 这种工作方式的时
间成本和人力成本较高, 很难在有限时间内达到较好效果 [4] .
为了提高数据库系统参数调优的工作效率, 工业界和学术界开始尝试采用基于搜索 [5,6] 和学习 [2,7,8] 的方法开展
[5]
自动化参数调优的研究. 基于搜索的方法 BestConfig 可以在给定的资源限制内推荐最佳配置, 但无法利用过往经
[7]
验. 基于学习的方法, 如 OtterTune , 它利用机器学习的高斯过程回归 (GPR) 方法来自动学习和推荐参数配置, 但
此类方法需要大量的高质量训练样本. 由于高斯过程回归 (GPR) 方法是在高维连续空间中获取最优参数的过程,
基于此方法的数据库系统参数优化难以获得最优解. CDBTune +[2] 采用基于 DDPG (deep deterministic policy gradient)
的深度强化学习方法实现数据库系统参数的自动化优化, 解决了传统机器学习方法依靠大量高质量训练样本、在
[9]
高维连续空间中难以获取最优参数的难题. QTune 基于数据库系统当前的状态信息和 SQL 查询语句的信息使用
两状态的深度确定性策略梯度模型 (double states DDPG, DS-DDPG), 能够在更细粒度的层面上对数据库系统配置
参数进行性能优化. Gur 等人 [10] 提出了一种基于 DDPG 的多模型数据库系统参数优化方法, 解决生产环境中可能
出现的负载和软件、硬件环境发生变化的情况.
以上基于 DDPG 模型的优化方法虽然都取得了一定的效果, 但是都把本质上是多目标优化任务的数据库参
数调优, 通过线性组合将多个目标转换成了单个目标, 来使用传统的单目标强化学习模型, 降低了强化学习模型使
用的难度, 但也存在以下几个问题需要改进.
(1) 提前确定偏好是一项繁琐且具有盲目性的任务. 在训练 DDPG 模型之前需要根据预先设置的偏好定制标