
Page 450 - 《软件学报》2025年第10期
P. 450
孙锐 等: 隐式多尺度对齐与交互的文本-图像行人重识别方法 4847
purer person features, which is helpful for alleviating the information inequality between images and texts. Experimental results on three
mainstream text-image person re-identification datasets of CUHK-PEDES, ICFG-PEDES and RSTPReid show that the proposed method
effectively improves the cross-modal retrieval performance, which is 2%‒9% higher than the Rank-1 of SOTA algorithm.
Key words: text-image person re-identification; implicit alignment; multi-scale fusion; multivariate interaction attention; semantic alignment
行人重识别 ReID (person re-identification) 是智能视频监控领域的一项基本任务. 其目的是根据给定的检索条
件 (如人物图像, 相关属性或自然语言描述) 在多个非重叠相机中查询目标行人. 根据查询的模态, 行人重识别任
务大致可分为基于图像的搜索 [1,2] 、基于属性的搜索 [3,4] 和基于文本的搜索 [5,6] . 但是现有的行人重识别方法通常忽
略了一些复杂或特殊场景下无法获得行人图像的情况. 例如一些偏远的道路没有监控探头或行人完全被遮挡 [7] .
为了解决这个问题, 警方可根据目击者提供的语言描述来搜索目标行人, 即文本-图像行人重识别 TIReID (text-
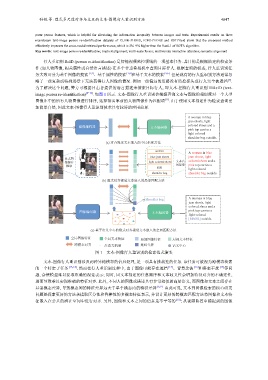
image person re-identification) [8−12] . 如图 1 所示. 文本-图像行人重识别会根据查询文本与图像的相似度对一个大型
图像库中的所有人物图像进行排序, 选择排名靠前的人物图像作为匹配项 [6] . 由于使用文本描述作为检索查询更
加简单自然, 因此文本-图像行人重识别技术具有较好的应用前景.
A woman in blue
jean shorts, light
图像编码器 文本编码器 colored shoes and a
pink top carries a
light colored
shoulder bag outside.
(a) 对齐视觉文本嵌入的全局匹配方法
woman
A woman in blue
blue jean shorts jean shorts, light
显式图
像部分 light colored shoes 文本名 colored shoes and a
提取 词提取 pink top carries a
pink
light colored
shoulder bag shoulder bag outside.
(b) 显式对齐视觉文本嵌入的局部匹配方法
Shoulder bag A woman in blue
jean shorts, light
colored shoes and a
图像编码器 文本编码器 pink top carries a
light colored
[MASK] outside.
(c) 基于语义中心的隐式对齐视觉文本嵌入的全局匹配方法
全局图像特征 全局文本特征 局部图像特征 局部文本特征
跨模态对齐 注意力机制 掩码令牌 语义中心
图 1 文本-图像行人重识别的检索范式演变
文本-图像行人重识别涉及两种异构模态的信息处理, 是一项具有挑战性的任务. 该任务可被视为跨模态检索
的一个特定子任务 [13,14] . 然而在行人重识别过程中, 由于图像可能存在遮挡 [15] 、背景杂波 [16] 和姿态干扰 [17] 等问
题, 会使模型难以提取准确的视觉表示; 同时, 因文本描述的任意顺序和文本歧义性会增加特征对齐的不确定性,
进而导致难以实现准确的特征对齐. 此外, 不同人的图像或描述具有非常相似的高层语义, 而图像和文本之间存在
显著模态差异, 导致模态间的特征差异远大于单个模态内的特征差异 [6,9] . 由此可见, 文本到图像检索的核心研究
问题是探索更好的方法来提取区分性和鲁棒性的多模态特征表示, 并设计更好的跨模态匹配方法将图像和文本特
征嵌入在公共的潜在空间中进行对齐. 另外, 图像和文本之间的信息是不平等的 [18] : 从视频监控中捕捉到的图像