
Page 368 - 《软件学报》2025年第10期
P. 368
刘一丁 等: 针对 LLM 对话属性情感理解的多代理一致性反思 4765
4.5 多代理一致性反思方法关键超参数的有效性分析
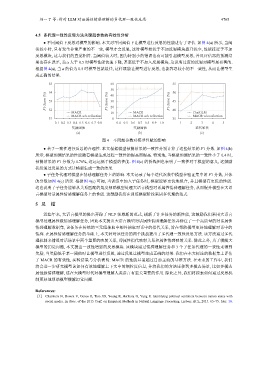
● 不同阈值下反思对模型的影响. 本文对不同阈值下让模型进行反思的性能进行了评估. 如图 4(a) 所示, 当阈
值较小时, 只有发生非常严重的不一致, 模型才会反思, 这时模型相较于不加反思模块提升较少, 性能接近于不加
反思模块, 这与我们的直觉相符. 当阈值较大时, 因为特别小的错误也有可能引起模型反思, 并且评估器的预测结
果也存在误差, 当 α 大于 0.5 时模型性能快速下降, 甚至低于不加入反思模块, 这说明过度的反思对模型是有害的.
根据图 4(a), 当 α 的值为 0.5 时模型性能最佳, 这样既能让模型进行反思, 也能容忍较小的不一致性, 从而让模型生
成正确的结果.
55 60 55
50 50
54
F1-Score (%) 53 F1-Score (%) 40 F1-Score (%) 45
30
52
MACR 20 MACR 40 ChatGLM
10
MACR w/o reflection MACR w/o reflection MACR w/o reflection
51 0 35
0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.4 0.5 0.6 0.7 0.8 0.9 1.0 1 2 3 4 5
奖励阈值 奖励阈值 迭代轮次
(a) (b) (c)
图 4 不同超参数对模型性能的影响
● 基于一致性进行反思的合理性. 本文根据模型预测结果的一致性分别计算了这些结果的 F1 分数. 如图 4(b)
所示, 模型预测结果的性能随着模型生成过程一致性的提高而提高. 特别地, 当模型预测结果的一致性小于 0.4 时,
预测结果的 F1 分数为 4.76%, 这远远低于模型的性能. 图 4(c) 的折线图也表明了一致性对于模型的意义, 这鼓励
我们通过反思的方式让模型生成一致的结果.
● 子任务代理对模型在情感理解任务上的影响. 本文记录了每个迭代次数中模型在验证集中的 F1 分数, 具体
的分数如图 4(c) 所示. 根据图 4(c) 可知, 当训练中加入子任务时, 模型能够更快地拟合, 并且模型有更优的性能.
这也说明了子任务能够从关系匹配的角度帮助模型处理大语言模型对话属性情感理解任务, 从而提升模型在大语
言模型对话属性情感理解任务上的性能. 这鼓励我们在训练模型阶段采用多代理的范式.
5 总 结
近些年来, 大语言模型的提出开辟了 NLP 领域新的范式, 刷新了许多任务的新性能, 这鼓励我们采用大语言
模型处理属性级情感理解任务, 因此本文提出大语言模型对话属性情感理解任务并标注了一个高质量的对话属性
情感理解数据集, 该任务在传统的三元组抽取中额外抽取对话中的指代关系, 旨在帮助模型更好地理解对话中的
情感. 在属性情感理解任务的基础上, 本文针对该任务的两个挑战提出了多代理一致性反思方法. 该方法通过多代
理机制来捕捉对话场景中两个重要的映射关系, 即属性指代映射关系和属性情感映射关系. 除此之外, 为了缓解大
模型的幻觉问题, 本文提出一致性增强的反思模块. 该模块通过情感理解任务和 3 个子任务代理的一致性来得到
奖励, 当奖励低于某一阈值时让模型进行反思, 通过反思让模型生成正确的结果. 我们在本文标注的数据集上评估
了 MACR 的有效性, 实验结果与分析表明: MACR 的性能显著超过目前主流的基准方法. 在未来的工作中, 我们
将会进一步研究模型该如何有效地理解上下文中的细粒度信息, 并将我们的方法迁移到多模态场景, 比如多模态
属性级情感理解, 这在大模型时代对模型理解人类语言有至关重要的作用. 除此之外, 我们将探索如何通过反思机
制更好地帮助模型缓解幻觉问题.
References:
[1] Chambers N, Bowen V, Genco E, Tian XS, Young E, Harihara G, Yang E. Identifying political sentiment between nation states with
social media. In: Proc. of the 2015 Conf. on Empirical Methods in Natural Language Processing. Lisbon: ACL, 2015. 65–75. [doi: 10.