
Page 302 - 《软件学报》2025年第10期
P. 302
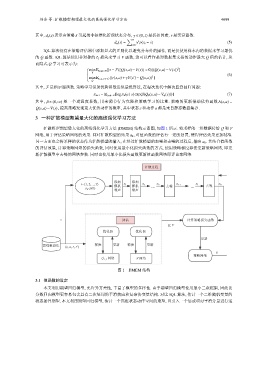
刘全 等: 扩散模型期望最大化的离线强化学习方法 4699
r
其中, d π (s) 表示由策略 π 引起的非标准化折现状态分布, γ ∈ (0,1) 是折扣因素, 是奖赏函数.
∑
∞
t
d π (s) = γ p(s t = s) (5)
t=0
IQL 算法没有在策略评估器中添加显式的正则化以避免分布外的操作, 而是仅使用样本内的数据来学习最优
的 Q 函数. IQL 算法使用非对称的 ℓ 2 损失来学习 V 函数, 这可以看作是对数据集支持的动作最大 Q 值的估计, 从
而隐式 Q 学习可表示为:
2
minE (s,a)∼D [|τ−F((Q(s,a)−V(s)) < 0)|(Q(s,a)−V(s)) ]
V
(6)
2
minE (s,a,s ′ )∼D [(r(s,a)+γV(s )− Q(s,a)) ]
′
Q
其中, F 是指示器函数. 策略学习借助优势函数近似最优算法, 在每次迭代中解决监督回归问题:
π k+1 = E (s,a)∼D [logπ k (a | s)exp(β(Qˆ θ (s,a)−V ψ (s)))] (7)
其中, β ∈ (0,∞) 是一个逆温度系数, 用来调节行为克隆和策略学习的比重. 策略的更新借助优势函数 A(s,a) =
s
D
Q(s,a)−V(s), 提高策略发现更大优势动作的概率, 其中状态 和动作 a 都是来自静态数据集 .
3 一种扩散模型期望最大化的离线强化学习方法
扩散模型期望最大化的离线强化学习方法 (DMEM) 结构示意图, 如图 1 所示. 将采样的一组数据传给 Q 和 V
网络, 用于评估策略网络的效果. 同时扩散模型的结果 a 0 , 对值函数的评估有一定的惩罚, 使得评估效果更加精准.
a 0 . 其结合值函数
另一方面也会将采样的状态作为扩散模型的输入, 在经过扩散模型的加噪和去噪的过程后, 输出
的评估效果, 计算策略网络的损失函数, 同时使用最小化损失函数的方式, 使用策略梯度算法更新策略网络, 即更
新扩散模型中去噪的网络参数. 同时也使用最小化损失函数更新值函数网络即评论家网络.
扩散过程
添加 添加
t~{1, 2,..., T} a 1 a 2 a T a T−1 a 1 去噪 a 0
a 0 ~p(0) 随机 随机 去噪
噪声 噪声
s 评估 计算策略损失函数
Q, V
优化器 优化器
更新
离线数据集 (s, a, r, r′) 梯度 更新 梯度 更新
θ
策略网络
Q 1, 2 网络 V 网络
图 1 DMEM 结构
3.1 值函数的设定
本文利用期望回归模型, 允许异方差性, 丰富了模型的多样性. 由于期望回归模型使用最小二乘框架, 因此比
分数回归模型更容易包含具有二次惩罚的平滑效应和复杂协变量结构. 对比 IQL 算法, 估计一个二维随机变量的
状态条件期望. 本文利用期望回归模型, 估计一个高维状态动作空间的期望, 且引入一个惩戒项对平滑分量进行适