
Page 324 - 《软件学报》2025年第9期
P. 324
韩将 等: 面向跨信任域互联网场景的拜占庭容错访问控制架构 4235
的优势, 实验 4 将分析 Super-Dumbo 中各个部分的时间占用率. 需要特别说明的是, 当 k = 1 时, 可以看作广播阶
段使用 RBC 或 PRBC, 即 Dumbo2 的广播阶段, 所以实验 2 主要是对 Dumbo2 和 Super-Dumbo 广播阶段进行性能
比较. 实验 1 和实验 2, 均进行了小规模 (PC 实验环境, 不多于 10 个仿真验证节点) 和大规模实验 (高性能服务器
实验环境, 最多 64 个仿真验证节点), 实验 3 和实验 4 仅进行小规模实验. 小规模实验环境为: 操作系统 Ubuntu
18.04 LTS, CPU 为 AMD Ryzen 7 6800H, RAM 大小 16 GB; 大规模实验环境为: 操作系统 Ubuntu 20.04 LTS, CPU
为 28-core Xeon Platinum 8280, RAM 大小 1 TB. 每个节点实例以线程进行, 通过 Python 库的 gevent. Queue 模拟
节点消息缓冲队列, 使用 socket 套接字进行网络通信, 并使用宽带限制和强制延迟模拟异步网络环境, 其中网络环
境分为良好的网络环境, 其带宽和延时分别设置为 200 Mb/s 和 50 ms, 以及差的网络环境, 为 50 Mb/s 和 300 ms,
在实验中会按一定规律进行切换. 实验中单笔交易的大小固定为 250 B.
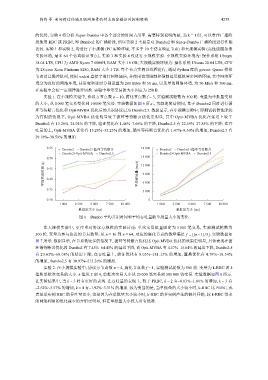
实验 1. 在小规模实验中, 协议方节点数 n = 10, 腐化节点数 f = 3, 实验测试轮数为 500 轮. 变量为单批量交易
的大小, 从 1 000 笔交易变化到 10 000 笔交易. 实验数据如图 6 所示, 为叙述简洁期间, 基于 Dumbo2 同时进行循
环等待断言优化和 Opti-MVBA 优化后的共识协议记为 Dumbo2.5. 数据显示, 在小规模实验中, 即测试机器性能较
为有限的情况下, Opti-MVBA 优化明显较于循环等待断言优化更明显, 其中 Opti-MVBA 优化在延迟上较于
Dumbo2 有 13.26%–24.94% 的下降, 验证优化有 1.46%–7.66% 的下降, Dumbo2.5 有 22.59%–27.85% 的下降; 在吞
吐量的上, Opti-MVBA 优化有 15.28%–33.23% 的增加, 循环等待断言优化有 1.47%–8.30% 的增加, Dumbo2.5 有
29.18%–38.59% 的增加.
0.55 18 000
Dumbo2 Dumbo2+循环等待断言 Dumbo2 Dumbo2+循环等待断言
Dumbo2+Opti-MVBA Dumbo2.5 Dumbo2+Opti-MVBA Dumbo2.5
15 000
0.50 12 000
平均共识时间 (s) 0.45 平均吞吐量 (txs/s) 9 000
0.40
0.35 6 000
3 000
0.30 0
1 000 2 500 5 000 7 500 10 000 1 000 2 500 5 000 7 500 10 000
单批量大小 (txs) 单批量大小 (txs)
图 6 Dumbo 平均共识时间和平均吞吐量随单批量大小的变化
在大规模实验中, 更注重对协议方规模的实验讨论: 单次交易批量固定为 5 000 笔交易, 实验测试轮数为
500 轮. 变量为参与协议的节点数量, 从 n = 16 到 n = 64, 对应的腐化节点的数量满足 f = ⌊(n−1)/3⌋. 实验数据如
图 7 所示. 数据显示, 在节点数较多的情况下, 循环等待断言优化比 Opti-MVBA 优化的效果更明显, 具体表现在循
环等待断言优化较 Dumbo2 有 7.45%–64.43% 的延迟下降, 而 Opti-MVBA 有 4.57%–15.64% 的延迟下降, Dumbo2.5
有 23.65%–68.08% 的延迟下降; 在吞吐量上, 验证优化有 8.05%–181.13% 的增加, 置换优化有 4.79%–18.54%
的增加, Dumbo2.5 有 30.97%–213.26% 的增加.
实验 2. 在小规模实验中, 协议方节点数 n = 4, 腐化节点数 f = 1, 实验测试轮数为 500 轮. 变量为 k-RBC 的 k
值和单批次交易的大小. k 值从 2 到 4, 单批次交易大小从 25 000 笔交易到 500 000 笔交易. 实验数据如图 8 所示.
在实验结果中, 当 k = 3 时有更好的表现. 在吞吐量的表现上, 较于 PRBC, k = 2 有–0.03%~1.80% 的增加, k = 3 有
–2.62%~3.57% 的增加, k = 4 有–1.92%~3.31% 的增加. 较为明显的是, 当单批量的大小较小时, k-RBC 比 PRBC, 或
者是单实例 RBC 的吞吐量更小, 这是因为在单批量大小较小时, k-RBC 的多实例产生的额外开销, 较 k-RBC 带来
的网络利用的优化减少的开销更明显, 但在单批量大小较大时有优势.