
Page 306 - 《软件学报》2025年第9期
P. 306
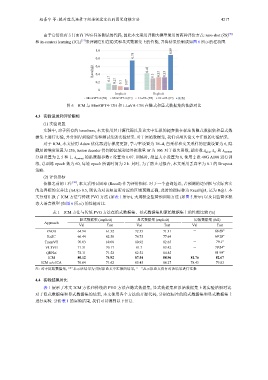
赵嘉宁 等: 提升隐式场景下短语视觉定位的因果建模方法 4217
由于它们没有专门面向 PVG 任务测试的代码, 因此本文采用评测大模型常用的两种评价方式: zero-shot (ZS) [50]
和 in-context learning (ICL) [51] 来评测它们在隐式和显式数据集上的性能, 并将结果绘制成如图 6 所示的柱状图.
1.0 0.89
0.75
0.8
Recall@1 0.6 0.43 0.3 0.33 0.33
0.4
0.2 0.17 0.13 0.1 0.07
0
Implicit Explicit
MiniGPT-4 (ZS) MiniGPT-4 (IC) LLaVA (ZS) LLaVA (IC) ICM
图 6 ICM 与 MiniGPT4-13B 和 LLaVA-13B 在隐式和显式数据集的性能对比
4.3 实验设置和评价指标
(1) 实验设置
实验中, 对于所有的 baselines, 本文使用其开源代码以及论文中汇报的超参数在标注的隐式数据集和显式数
据集上进行实验, 并分别得到验证集和测试集的实验结果. 对于原始数据集, 我们引用其论文中汇报的实验结果.
对于 ICM, 本文使用 Adam 优化器进行梯度更新, 学习率设置为 1E–4, 自采样和交叉采样的层数设置为 6, 隐
藏层的维度设置为 256, fusion decoder 得到的区域和边界框数量 M 为 100. 对于损失函数, 超参数 λ giou ,λ L1 和 λ contrast
分别设置为 2, 5 和 1, λ contrast 的温度超参数 τ 设置为 0.07. 训练时, 批量大小设置为 8, 使用 2 张 40G A100 进行训
练, 总训练 epoch 数为 60, 每轮 epoch 所需时间为 2 h. 同时, 为了防止过拟合, 本文采用丢弃率为 0.1 的 Dropout
策略.
(2) 评价指标
依据之前的工作 [46] , 本文采用召回率 (Recall) 作为评价指标. 对于一个查询短语, 若预测的边界框与实际真实
的边界框的交并比 (IoU) ⩾ 0.5, 则认为对该短语所对应的区域预测正确, 此时的指标称为 Recall@1, 记为 R@1. 本
文分别汇报了 ICM 方法与传统 PVG 方法 (如表 1 所示), 大规模全监督预训练方法 (如图 5 所示) 以及自监督多模
态大语言模型 (如图 6 所示) 的性能对比.
表 1 ICM 方法与传统 PVG 方法在隐式数据集、显式数据集和原始数据集上的性能比较 (%)
隐式数据集 (implicit) 显式数据集 (explicit) 原始数据集 (full)
Approach
Val Test Val Test Val Test
FAOA 64.94 61.32 72.35 71.31 - 68.69 ∗
ReSC 66.44 62.58 76.75 77.64 - 69.28 ∗
TransVG 70.03 69.08 80.92 82.65 - 79.1 ∗
VLTVG 71.31 70.17 81.7 83.42 - 79.84 ∗
QRNet 72.11 71.52 82.52 84.85 - 81.95 ∗
ICM 80.12 74.92 87.54 88.96 81.76 82.67
ICM w/o ICA 76.64 71.62 85.45 86.27 78.43 79.83
注: 对于原始数据集, “*”表示该结果为引用原论文中汇报的结果, “-”表示原论文没有对该结果进行汇报
4.4 实验结果对比
表 1 展示了本文 ICM 方法和传统的 PVG 方法在隐式数据集, 显式数据集和原始数据集上的实验结果对比.
对于隐式数据集和显式数据集的结果, 本文使用各个方法的开源代码, 分别在标注的隐式数据集和显式数据集上
进行实验. 分析表 1 的实验结果, 我们可以得到以下信息.