
Page 137 - 《软件学报》2025年第9期
P. 137
4048 软件学报 2025 年第 36 卷第 9 期
于 CBT-G.
通过对比表 3 中的 CBT-P 和 CBT-G 可以发现, CBT-P 的各项评估指标略低于 CBT-G, 这说明即使 CBT-G
存在数据不均衡性问题的情况下, 两个模态数据的融合也能在一定程度上缓解 bug 报告文本数据模态单一对 bug-
开发者相关性欠表征带来的影响, 这充分说明将两种模态数据融合分析可以对 CBT-MF 的 bug 分派性能提升产
生积极的作用.
此外, 为了评估同一数据集不同程度修复记录关联分布不均衡性对 CBT-MF 性能的影响, 实验根据表 1 所示
的修复记录数, 将 GC、MC、MF 这 3 个数据集中的所有 bug 报告记录和开发人员依次分成 G1–G5 这 5 个数据
组, 保持每一组中的 bug 修复记录数和开发人员数量不变. 其中, 较小 ID 的数据组, 包含的 bug 报告较新, 需要修
复的时间跨度大, 且数据组的 bug 报告记录规模大、数量多; 相同的 bug 修复记录数的条件下, 相对于其他同等数
量开发者的大 ID 数据组来讲, 数据不均衡的可能性更大. 例如, 与大 ID 组相比, 在相同修复记录、相同开发人员
数量下, 包含较多修复记录的 G1 表示在数据组中开发人员修复的 bug 相对较少, 意味着数据组的修复记录关联
分布不均衡性更强. 各数据组仍然以 8:1:1 的比例分为训练集、验证集及测试集, 并与整体性能较优的 SGL 方法
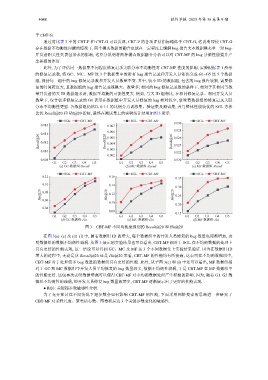
比较 Recall@20 和 Hit@20 指标, 最终在测试集上的实验统计结果如图 3 所示.
SGL CBT-MF SGL CBT-MF SGL CBT-MF
0.030
0.016 0.007
0.028
0.006
0.014
Recall@20 0.012 Recall@20 0.005 Recall@20 0.026
0.004
0.024
0.010 0.003
0.022
0.002
0.008 0.020
G1 G2 G3 G4 G5 G1 G2 G3 G4 G5 G1 G2 G3 G4 G5
(a) GC 数据组-Recall (b) MC 数据组-Recall (c) MF 数据组-Recall
SGL CBT-MF SGL CBT-MF SGL CBT-MF
0.12 0.16
0.35
0.10 0.14
0.30
Hit@20 0.08 Hit@20 0.12 Hit@20 0.25
0.06
0.10
0.20
0.04
0.08
0.15
G1 G2 G3 G4 G5 G1 G2 G3 G4 G5 G1 G2 G3 G4 G5
(d) GC 数据组-Hit (e) MC 数据组-Hit (f) MF 数据组-Hit
图 3 CBT-MF 不同均衡度级别的 Recall@20 和 Hit@20
在图 3(a)–(c) 及 (d)–(f) 中, 随着数据组 ID 的增大, 每个数据组中的开发人员修复的 bug 数量也逐渐增加, 表
明数据组的数据不均衡性减弱. 从图 3 展示的实验结果也可以看出, CBT-MF 相对于 SGL 在不均衡数据的处理上
具有更好的性能表现, 这一结论可以得到 GC、MC 及 MF 这 3 个不同数据集上实验结果验证. 因为在数据组 ID
增大的过程中, 无论是从 Recall@20 还是 Hit@20 来看, CBT-MF 的性能均有所提高, 这表明在不均衡数据组中,
CBT-MF 对于处理较多 bug 数量的数据组具有更好的性能. 此外, 从子图 3(c) 和 (f) 中还可以看出, MF 数据组相
对于 GC 和 MC 数据组中开发人员平均修复的 bug 数量较多, 数据不均衡性较弱, 于是 CBT-MF 在 MF 数据组中
的性能更好. 这也再次表明数据增强可以使得 CBT-MF 对不均衡数据处理产生积极的影响. 因为, 随着 G1–G5 数
据组不均衡性的减弱, 即开发人员修复 bug 数量的增多, CBT-MF 逐渐展示出了更好的性能表现.
● RQ3: 关键超参数敏感性分析.
为了充分探讨在不同情况下超参数会如何影响 CBT-MF 的性能, 下面采用网格搜索的思路进一步研究了
CBT-MF 对采样尺度、聚类质心数、图卷积层这 3 个关键参数变化的敏感性.