
Page 67 - 《软件学报》2025年第8期
P. 67
3490 软件学报 2025 年第 36 卷第 8 期
F droplasts 问题上的内存成本对比. 显著地, Metagol AI_ 在全局堆栈限制下推理大幅减少, 平均减幅
F
Metagol AI_ 在
约为 46.12%. 与 Metagol A 相比, Metagol AI_ 需要更少的子句垃圾收集.
F
I
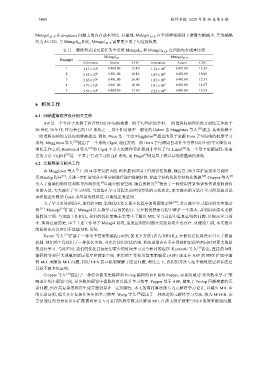
表 11 删除列表尾元素任务中系统 Metagol A 和 I Metagol AI_ 之间的内存成本比较
F
Metagol AI Metagol AI_F
Example
Inferences Atoms CGC Inferences Atoms CGC
1 3.17×10 6 6 400.90 15.10 1.74×10 6 6 401.00 12.33
2 3.53×10 6 6 401.00 18.10 1.83×10 6 6 401.00 16.00
3 3.63×10 6 6 401.00 16.90 1.82×10 6 6 401.00 15.33
4 3.77×10 6 6 401.00 16.40 1.91×10 6 6 401.00 14.67
5 3.57×10 6 6 400.90 17.50 2.22×10 6 6 401.00 15.33
6 相关工作
6.1 归纳逻辑程序设计相关工作
ILP 是一个专注于从例子和背景知识中归纳构建一阶子句理论的学科. 一阶逻辑归纳理论的开创性工作始于
20 世纪 70 年代. 作为著名的 ILP 系统之一, 基于相对最不一般化的 Golem 由 Muggleton 等人 [23] 提出. 其他依赖于
一阶逻辑归纳的方法也相继被提出. 例如, Duce 是一个由 Muggleton [24] 提出的基于命题 Horn 子句归纳的机器学习
系统. Muggleton 等人 [22] 提出了一个系统 Cigol, 通过发明一阶 Horn 子句谓词自动补全背景知识中的不完整信息.
继此工作之后, Rouveirol 等人 [25] 将 Cigol 中引入的操作符扩展到非单位子句. Linus [26] 是一个基于命题属性-值语
[4]
言的方法. CLINT [27] 是一个基于主动学习的 ILP 系统, 而 Progol 则是基于模式导向逆蕴涵的系统.
6.2 元解释学习相关工作
由 Muggleton 等人 [2] 于 2014 年开发的 MIL 框架最初应用于归纳语法推断, 随后在 2015 年扩展到学习高阶二
元 Datalog 程序 [15] , 并进一步扩展到从少量实例进行递归数据转换, 涵盖半结构化和非结构化数据 [28] . Cropper 等人 [8]
引入了蕴涵约简算法和推导约简算法 [9] 以减少假设空间. 随后的研究 [29] 提出了一种使用背景知识预先识别假设约
束的方法, 大大减少了学习时间. 与这些在学习过程之前应用算法的方法相比, 本文提出的方法在学习阶段通过记
录和检查失败的 Goals 来应用剪枝算法, 以避免重复证明.
为了学习更好的程序, 现有的 MIL 系统优化要么最小化程序的资源复杂性 [30] , 要么减少学习程序的文本复杂
性 [21] . Metaopt [19] 扩展了 Metagol 以支持学习高效的程序. 它在假设搜索过程中维护一个成本, 并利用该成本来修
剪假设空间. 与这些工作相比, 我们的优化策略主要集中于解决 MIL 学习过程中重复证明的问题, 以提高学习效
率. 值得注意的是, 由于上述工作基于 Metagol 系统, 重复证明的问题在这些系统中也存在. 从理论上讲, 本文提出
的算法也可以应用于这些 MIL 系统.
Kazmi 等人 [31] 扩展了一种基于答案集编程 (ASP) 的 ILP 方法 (名为 XHAIL), 在假设泛化算法中引入了修剪
机制. 他们的工作使用了一种优化方法, 并允许使用次优结果. 其改进重点在于在保持相似质量的同时对更大数据
集进行学习. 与此不同, 我们的优化目标是用更少的时间学习完全相同的程序. Kaminski 等人 [32] 指出, 直接的 MIL
编码将导致巨大规模的底层程序和搜索空间. 他们的工作使用答案集编程 (ASP) 通过在 ASP 的 HEX 扩展中编
码 MIL 来解决 MIL 问题, 利用 HEX 接口机制缓解了底层问题. 相比之下, 我们的方法专注于确保底层和非底层
目标不被多次证明.
Cropper 等人 [33] 提出了一种结合答案集编程和 Prolog 编程的 ILP 系统 Popper, 该系统通过“从失败中学习”策
略逐步缩小假设空间, 从失败的假设中提取约束以提升学习效率. Popper 基于 ASP, 避免了 Prolog 回溯搜索的冗
余问题, 但在高复杂度程序生成方面仍存在一定局限性. 本文的剪枝算法则专为元解释学习设计, 以减少 MIL 中
的冗余证明, 提升其在复杂任务中的学习效率. Wang 等人 [34] 提出了一种改进的元解释学习方法, 称为 MILER, 该
方法通过向背景知识中扩展谓词来引入可复用的程序模式以解决 MIL 在庞大程序搜索空间中的效率限制问题.