
Page 65 - 《软件学报》2025年第8期
P. 65
3488 软件学报 2025 年第 36 卷第 8 期
表 7 和表 8 提供了一阶 MIL 系统 Metagol、Metagol F 以及高阶 MIL 系统 Metagol AI 、Metagol AI_ 在执行机器
F
人服务员任务期间内存消耗的对比分析. 分析表明, 优化版本 Metagol F 和 Metagol AI_ 在推理次数上显著减少, 从
F
而提高了计算效率. 对于一阶系统, Metagol F 相较于 Metagol 实现了约 44.18% 的平均推理次数减少. 同样, 在高阶
系统中, Metagol AI_ 相较于 Metagol A 实现了约 42.80% 的平均推理次数减少. 这些显著的改进突显了优化系统中
F
I
剪枝技术的有效性, 展示了其在处理具有更高计算效率、较低原子数和较少子句垃圾收集 (CGC) 能力的任务方
面的优势, 且此改进在 Prolog 默认 256 MB 堆栈限制下得以实现.
表 7 在机器人服务员任务中, 一阶 MIL 系统 表 8 在机器人服务员任务中, 高阶 MIL 系统
Metagol 与 Metagol F 之间的内存成本比较 Metagol A 与 I Metagol AI_ 之间的内存成本比较
F
Metagol Metagol F Metagol AI Metagol AI_F
Example Example
Inferences Atoms CGC Inferences Atoms CGC Inferences Atoms CGC Inferences Atoms CGC
9
9
9
1 1.64×10 6 373.33 7.25 1.10×10 6 360.33 6.50 1 1.81×10 6 444.29 8.29 1.07×10 6 350.67 7.00
9
9
9
9
9
2 3.22×10 6 359.67 7.67 1.60×10 6 340.33 6.50 2 2.74×10 6 444.67 8.67 1.89×10 6 340.33 7.50
9
9
9
3 4.49×10 6 331.33 8.33 2.13×10 6 320.33 7.00 3 4.54×10 6 445.00 9.00 2.23×10 6 320.33 8.33
9
9
9
4 3.42×10 6 388.33 9.33 2.30×10 6 370.67 8.00 4 4.89×10 6 444.67 10.00 2.90×10 6 370.67 9.00
9
9
9
9
9
9
5 4.45×10 6 388.33 9.00 2.12×10 6 375.67 8.50 5 4.65×10 6 445.00 10.00 2.30×10 6 375.33 8.50
5.3 象棋策略
本实验的设置与文献 [21] 相同. 此学习任务旨在学习一个简单的国际象棋策略, 即维持一道黑卒的防线以实
现升变. 在初始状态下, 卒子被放置在不同的横行上, 而在最终状态下, 它们位于第 8 行, 这里忽略了白方的干扰.
我们随机生成了 5 组不同大小的训练集, 大小范围为 1–5, 设定时间限制为 600 s, 然后使用上述 4 个系统学习这
个国际象棋策略. 经过 10 次实验后, 我们得到了结果.
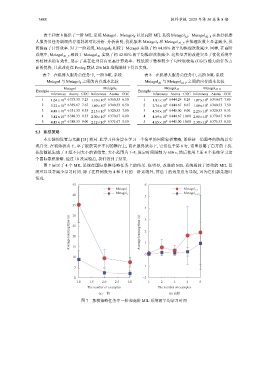
图 7 展示了 4 个 MIL 系统在国际象棋策略任务上的结果. 很明显, 改进的 MIL 系统相较于原始的 MIL 系
统可以显著减少学习时间. 除了在样例数为 4 和 5 时的一阶系统外, 算法 1 的效果没有显现, 因为它们都是超时
情况.
45 6
Metagol Metagol AI
40 Metagol F Metagol AI_F
5
35
4 3
30
Average learning time (s) 25 Average learning time (s) 2 1
20
15
0
10
−1
5
0 −2
1.0 1.5 2.0 2.5 3.0 1 2 3 4 5
The number of examples The number of examples
(a) 一阶 (b) 高阶
图 7 象棋策略任务中一阶和高阶 MIL 系统的平均学习时间