
Page 33 - 《软件学报》2025年第8期
P. 33
3456 软件学报 2025 年第 36 卷第 8 期
如图 9 所示, 在验证 MNIST 数据集的任务中, 我们在 57.3% 的任务中实现了加速, 最高加速 26.94 倍, 比
Marabou 多解决了 3 个验证任务. 这里我们并未使用对数坐标轴, 因为能验证出来的性质多数集中在 10 000 s 以
内. 随着权重变化率的提高, 加速效果略有下降, 这是因为随着扰动大小的增加, 能够复用的证明减少. 我们同样测
试了在性质发生变化 (扰动半径分别增加 10%、50% 和 100%) 下的结果, DeepInc 仅在 40% 的任务上实现了加速,
但总体时间仍然比 Marabou 缩短了 1.44 h. 扰动半径的增加一定会改变神经元的上下界, 因此能够继承的证明大
大减少, 这也是性质发生改变时, 我们的方法的加速效果有所减弱的主要原因.
3.2 不同修改规模下的性能分析
我们针对 DeepInc 在不同修改规模下的性能进行了一系列测试. 一个重要的指标是在增量模式下直接证明出
UNSAT (即不运行算法 2 的第 11 行) 的 UNSAT 叶节点的百分比. 对于所有权重变化的 4 个权重变化率 0.001、
0.01、0.03 和 0.05, 这个百分比分别是 89.01%、85.77%、9.43% 和 85.84%. 对于部分权重变化的实验, 这个百分
比是 88.45%. 这表明, 当权重变化率 0.001–0.05 逐渐变化时, 我们增量求解的核心性能并没有显著下降. 从图 7 和
图 8 可以看出, 随着权重变化率的增加, DeepInc 的效率优势趋于减小, 尽管仍有少数验证问题中 DeepInc 快了 10
倍以上. 这种现象是合理的, 因为较大的修改不利于增量验证.
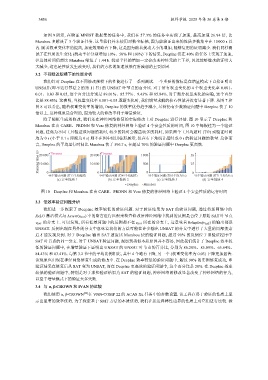
除了随机生成的修改, 我们还在神经网络修复的实际修改上对 DeepInc 进行评估. 图 10 显示了 DeepInc 和
Marabou 在由 CARE、PRDNN 和 Vere 修复的神经网络上验证 4 个安全性质的时间, 图 10 中每根柱为一个验证
问题, 柱高为不同工具验证该问题的耗时, 较少的耗时会覆盖较多的耗时, 如果两个工具均超时 (TO) 或验证时间
均为 0 s (小于 0.1 s 即视为 0 s) 则不在图中使用柱形展示, 仅在右下角统计超时或 0 s 的验证问题的数量. 总体而
言, DeepInc 的平均运行时间比 Marabou 快了 596.7 s, 在超过 70% 的验证问题中 DeepInc 更高效.
20 000 Timeout 20 000 Timeout 1 000 50
Running time (s) 10 000 10 000 500 25
0
48个验证问题 (有13个均超时) 0 94个验证问题 (有49个均超时) 0 95个验证问题 (有65个均为0 s) 0 95个验证问题 (有71个均为0 s)
4
(a) 安全性质 1 (b) 安全性质 2 (c) 安全性质 3 (d) 安全性质 4
DeepInc Marabou
图 10 DeepInc 和 Marabou 在由 CARE、PRDNN 和 Vere 修复的神经网络上验证 4 个安全性质的运行时间
3.3 低效率验证问题分析
我们进一步探索了 DeepInc 效率较低的验证问题. 对于验证结果为 SAT 的验证问题, 通过将新网络中的
ReLU 激活模式与 Assert(v SAT ) 中的断言进行匹配来检查修改后神经网络中找到的反例是否位于原始 SAT 叶节点
v SAT 的分支上. 可以发现, 所有低效问题中的反例都不在 v SAT 所在的分支上, 这意味着 Reluplex(v SAT ) 的输出都是
UNSAT. 反例出现在另外的分支中意味着我们的方法可能在许多输出 UNSAT 的分支中进行了大量的局部搜索
后才能发现反例. 对于 DeepInc 输出 SAT 速度比 Marabou 快的验证问题, 超过 90% 的反例位于旧验证程序中
SAT 叶节点的同一分支. 对于 UNSAT 验证问题, 观察到类似本质原因并不容易, 因此我们统计了 DeepInc 效率较
低的验证问题中, 在增量验证下证明出 UNSAT 的 UNSAT 叶节点的百分比, 分别为 86.20%、85.09%、65.64%、
84.43% 和 83.41%. 与第 3.2 节中的平均比例相比, 其中 4 个略有下降, 另一个 (权重变化率为 0.03) 下降更加显著.
该现象也出现在神经网络修复生成的修改中. 在 DeepInc 效率较低的验证问题中, 超过 90% 的实例修复成功, 即
验证结果在修复后从 SAT 变为 UNSAT, 而在 DeepInc 更高效的验证问题中, 这个百分比是 20%. 在 DeepInc 效率
较低的验证问题中, 特别是对于那些验证结果为 SAT 的验证问题, 神经网络的修改显著改变了神经网络的行为,
以至于增量模式下的验证大多失败.
3.4 与 α, β-CROWN 和 IVAN 的比较
我们使用 α, β-CROWN [26] 在 VNN-COMP 22 的 ACAS Xu 任务中的参数设置. 该工具在易于验证的性质上显
示出显著的效率优势. 为了探索基于 SMT 方法的本质优势, 我们在接近鲁棒性边界的性质上对它们进行比较. 验