
Page 467 - 《软件学报》2025年第5期
P. 467
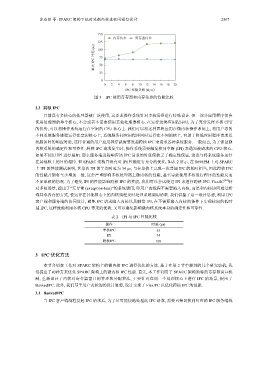
苏浩然 等: SPARC 架构下低时延微内核进程间通信设计 2367
150
内存传参 寄存器传参
125
单次 IPC 时延 (μs) 75
100
50
25
0
0 2 4 6 8 10 12 14 16 18 20
IPC 传输负载 (Byte)
图 3 IPC 使用寄存器和内存传参的性能比较
2.3 跨核 IPC
目前具有多核心的处理器被广泛使用, 这要求操作系统针对多核场景进行特殊设计. 但一部分应用程序仅会
使用处理器的单个核心, 不会或者不需要使用其他处理器核心. 在运行这类应用程序时, 为了充分发挥多核 CPU
的优势, 可以将操作系统运行在空闲的 CPU 核心上. 我们可以将这种思想应用在微内核操作系统上, 将用户态的
不同系统服务进程运行在空闲核心上, 系统服务和应用程序同时运行在不同的核上, 有助于降低应用程序请求系
统服务时的响应时延, 这样普通的用户应用程序就需要发起跨核 IPC 来请求各种系统服务. 一般而言, 为了保证微
内核系统的确定性和可靠性, 跨核 IPC 请求发生时, 操作系统需要触发核间中断 (IPI) 来通知被请求的 CPU 核心.
如果不使用 IPI 进行通知, 那么服务端进程响应该 IPC 请求的时延便缺乏了确定性保证, 这也与将系统服务运行
在其他核上的目的相悖. 但 SPARC 架构并没有对 IPI 性能进行充分的优化, 如表 2 所示, 在 S698PM 上对 SPARC
上 IPI 的性能测试表明, 其单次 IPI 的平均时延为 34 μs, 与在单核上完成一次普通 IPC 的耗时相当, 因此跨核 IPC
的性能开销将至少增加一倍, 这会严重影响多核处理器上微内核的性能, 甚至导致使用多核运行程序的性能反而
不如单核的情况. 为了避免 IPI 的性能影响跨核 IPC 的性能, 我们可以尝试绕过 IPI 来进行跨核 IPC. FlexSC [36] 针
对多核场景, 提出了“无异常 (exception-less)”的系统调用, 即用户态线程不需要陷入内核, 而是和内核协同通过轮
询共享内存的方式, 使运行在其他核心上的内核线程及时处理系统调用请求. 我们借鉴了这一设计思想, 利用 IPC
客户端和服务端的协同设计, 避免 IPC 请求陷入内核以及触发 IPI, 在不需要陷入内核的条件下实现核间的低时
延 IPC, 这样既能利用多核 CPU 带来的优势, 又可以避免影响微内核系统本身的确定性和可靠性.
表 2 IPI 与 IPC 性能比较
操作 时延 (μs)
单核IPC 55
IPI 34
跨核IPC 108
3 IPC 优化方法
本节介绍本工作对 SPARC 架构上的微内核 IPC 进行优化的方法. 基于在第 2 节中提到的几个研究动机, 我
们提出了两种方案优化 SPARC 架构上的微内核 IPC 性能. 首先, 本工作利用了 SPARC 架构独特的寄存器窗口机
制, 重新设计了内核对寄存器窗口的管理和分配算法, 主要针对在同一个处理核心上进行 IPC 的场景, 提出了
BankedIPC. 此外, 我们基于用户态轮询的设计思想, 设计实现了 FlexIPC 以优化跨核 IPC 的性能.
3.1 BankedIPC
当 IPC 客户端线程发起 IPC 请求后, 为了尽可能快地处理此 IPC 请求, 需要直接切换到对应的 IPC 服务端线