
Page 455 - 《软件学报》2025年第5期
P. 455
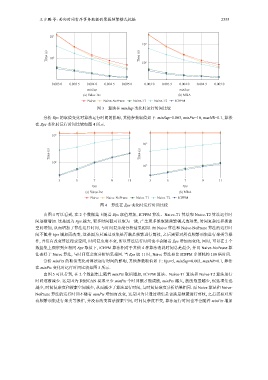
王少鹏 等: 面向时间有序事务数据的聚簇频繁模式挖掘 2355
10 3
10 3
Time (s) 10 2 Time (s)
10 2
0.003 0 0.003 5 0.004 0 0.004 5 0.005 0 0.003 0 0.003 5 0.004 0 0.004 5 0.005 0
minSup minSup
(a) Value-Inc (b) MBA
Naive Naive-NoPrune Naive-T1 Naive-T2 ICFPM
图 3 算法在 minSup 变化时运行时间比较
分析 Eps 的取值变化对算法运行时间的影响, 其他参数取值如下: minSup=0.003, minPts=10, maxNR=0.1, 算法
在 Eps 变化时运行时间比较如图 4 所示.
10 3
10 3
Time (s) Time (s)
10 2
10 2
3 5 7 9 11 3 5 7 9 11
Eps Eps
(a) Value-Inc (b) MBA
Naive Naive-NoPrune Naive-T1 Naive-T2 ICFPM
图 4 算法在 Eps 变化时运行时间比较
由图 4 可以看到, 在 2 个数据集上随着 Eps 取值增加, ICFPM 算法、Naive-T1 算法和 Naive-T2 算法运行时
间逐渐增加. 这是因为 Eps 越大, 更多时间戳可以聚为一簇, 产生更多候聚簇频繁模式选项集, 时间复杂度和搜索
空间增加, 从而增加了算法运行时间, 与时间复杂度分析结果相同. 而 Naive 算法和 Naive-NoPrune 算法的运行时
间不随着 Eps 增加而改变, 这是因为只通过项集是否满足频繁进行剪枝, 之后需要对所有频繁项集进行聚类等操
作, 并没有改变算法搜索空间, 时间复杂度不变, 所以算法运行时间也不会随着 Eps 增加而变化. 同时, 可以在 2 个
数据集上观察到在相同 Eps 取值下, ICFPM 算法相对于其他 4 种算法消耗时间总是最少, 并且 Naive-NoPrune 算
法要好于 Naive 算法, 与时间复杂度分析结果相同. 当 Eps 取 11 时, Naive 算法要比 ICFPM 多消耗约 100 倍时间.
分析 minPts 的取值变化对算法运行时间的影响, 其他参数取值如下: Eps=5, minSup=0.003, maxNR=0.1, 算法
在 minPts 变化时运行时间比较如图 5 所示.
由图 5 可以看到, 在 2 个数据集上随着 minPts 取值增加, ICFPM 算法、Naive-T1 算法和 Naive-T2 算法运行
时间逐渐减少. 这是因为 DBSCAN 要求至少 minPts 个时间戳才能成簇, minPts 越大, 簇的数量越少, 候选项集也
越少, 时间复杂度和搜索空间减少, 从而减少了算法运行时间, 与时间复杂度分析结果相同. 而 Naive 算法和 Naive-
NoPrune 算法的运行时间不随着 minPts 增加而改变, 这是因为只通过项集是否满足频繁进行剪枝, 之后需要对所
有频繁项集进行聚类等操作, 并没有改变算法搜索空间, 时间复杂度不变, 算法运行时间也不会随着 minPts 增加