
Page 367 - 《软件学报》2025年第5期
P. 367
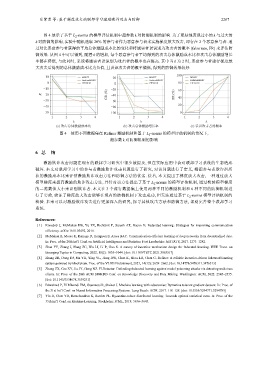
乐紫莹 等: 基于梯度放大的联邦学习激励欺诈攻击与防御 2267
图 4 展示了基于 L 2 -norms 的模型评估机制中超参数 k 对防御机制的影响. 为了更好地表现过小的 与过大的
k
k 对防御的影响, 实验中随机选取 20% 的参与者作为恶意参与者来实施梯度放大攻击, 即存在 2 个恶意参与者. 通
过对比恶意参与者获得的平均总体激励成本比的变化和将诚实者误识别为攻击者的概率 (false rate, FR) 来评估防
御效果. 从图 4 中可以得到, 随着 k 的增加, 每个恶意参与者平均得到的攻击总体激励成本比和攻击总体激励增长
率都在降低, 与此同时, 系统将诚实者误识别为攻击者的概率也在提高. 其中当 k 为 2 时, 恶意参与者进行梯度放
大攻击后得到的总体激励成本比为负值, 且误识攻击者的概率偏低, 得到的防御效果较好.
100
10 MNIST 20 MNIST MNIST
FashionMNIST FashionMNIST FashionMNIST
0 CIFAR10 0 CIFAR10 80 CIFAR10
−10 −20 60
R −20 GR (%) −40 FR (%) 40
−30 −60
−40 −80 20
−50 −100 0
1 2 3 4 1 2 3 4 1 2 3 4
k k k
(a) 攻击总体激励成本比 (b) 攻击总体激励增长率 (c) 误识攻击者的概率
图 4 使用不同数据集在 Refiner 激励机制和基于 L 2 -norms 的模型评估机制的情况下,
超参数 k 对防御机制的影响
6 总 结
激励欺诈攻击问题在现有的联邦学习研究中很少被提及, 但在实际应用中会对联邦学习系统的生态造成
破坏. 本文对联邦学习中的参与者激励欺诈攻击问题进行了研究, 对该问题进行了定义, 根据参与者欺诈后所
获的激励成本比来评估激励欺诈攻击方法和防御方法的优劣. 接着, 本文提出了梯度放大攻击, 一种通过放大
模型梯度来提高激励的欺诈攻击方法, 并针对该方法提出了基于 L 2 -norms 的模型评估机制, 通过检验模型梯度
的二范数值大小来识别欺诈者. 本文在 3 个流行数据集上使用两种不同的激励机制和 6 种不同的防御机制进
行了实验, 验证了梯度放大攻击能够在现有的防御机制下攻击成功, 但无法通过基于 L 2 -norms 模型评估机制的
检验. 未来可以对激励欺诈攻击进行更加深入的研究, 探寻其他攻击方法和防御方法, 帮助完善整个联邦学习
系统.
References:
[1] Konečný J, McMahan HB, Yu FX, Richtárik P, Suresh AT, Bacon D. Federated learning: Strategies for improving communication
efficiency. arXiv:1610.05492, 2016.
[2] McMahan B, Moore E, Ramage D, Hampson S, Arcas BAY. Communication-efficient learning of deep networks from decentralized data.
In: Proc. of the 20th Int’l Conf. on Artificial Intelligence and Statistics. Fort Lauderdale: AISTATS, 2017. 1273−1282.
[3] Zhan YF, Zhang J, Hong ZC, Wu LJ, Li P, Guo S. A survey of incentive mechanism design for federated learning. IEEE Trans. on
Emerging Topics in Computing, 2022, 10(2): 1035–1044. [doi: 10.1109/TETC.2021.3063517]
[4] Zhang ZB, Dong DJ, Ma YH, Ying YL, Jiang DW, Chen K, Shou LD, Chen G. Refiner: A reliable incentive-driven federated learning
system powered by blockchain. Proc. of the VLDB Endowment, 2021, 14(12): 2659–2662. [doi: 10.14778/3476311.3476313]
[5] Zhang ZX, Cao XY, Jia JY, Gong NZ. FLDetector: Defending federated learning against model poisoning attacks via detecting malicious
clients. In: Proc. of the 28th ACM SIGKDD Conf. on Knowledge Discovery and Data Mining. Washington: ACM, 2022. 2545–2555.
[doi: 10.1145/3534678.3539231]
[6] Blanchard P, El Mhamdi EM, Guerraoui R, Stainer J. Machine learning with adversaries: Byzantine tolerant gradient descent. In: Proc. of
the 31st Int’l Conf. on Neural Information Processing Systems. Long Beach: ACM, 2017. 118–128. [doi: 10.5555/3294771.3294783]
[7] Yin D, Chen YD, Ramchandran K, Bartlett PL. Byzantine-robust distributed learning: Towards optimal statistical rates. In: Proc. of the
35th Int’l Conf. on Machine Learning. Stockholm: ICML, 2018. 5636–5645.