
Page 160 - 《软件学报》2025年第4期
P. 160
1566 软件学报 2025 年第 36 卷第 4 期
表 6 TOP 数据集中不同少样本设置下不同模型的 F1 (%)
模型 zero-shot 50-shot
ZSBT 8.82 42.73
QASF 10.27 46.49
QASF w/ pre-training on WS 12.35 47.91
Ours 13.55 51.02
3.4.2 不同参数设置
本文采用了多实体生成的方式, 所以对不同领域中的话语存在的槽实体数量进行了统计, 其中对 TOP 数据集
我们只统计了其测试集的数量分布, 如表 7 所示. 可以看到大部分话语中存在的实体数量在 1–3 个, 可以侧面反映
出 SNIPS 和 TOP 这两个任务型数据集的单句文本中槽类型的强依赖组合保持在 3 个以内. 为了验证最适合建模
槽依赖的实体数量, 本文分别对不同槽数量构成的提示模板进行了实验. 如表 8 所示, 槽类型数量设置为 2 时模型
出现了最佳效果, 由此推断槽类型之间的隐式依赖更多地出现在两个槽类型之间. 设置为 1 时, 也就是之前的槽实
体独立生成方式, 缺少了槽类型之间的依赖信息, 模型的性能有较大幅度的下降. 相比较而言, 槽类型数量设置为
0.5
3 的效果更好, 依然能超过 AISFG 任务. 槽依赖信息的加入相比较 AISFG 中的领域和样例等多方信息更能发挥模
型的效果, AISFG 只是简单地增加了更多的启发知识, 而且人工构建的模板很难达到最佳性能, 我们通过可训练
的槽共享提示序列不仅引入了依赖信息, 而且可以不断调整到最佳表征.
表 7 不同领域共现槽数量统计 表 8 不同槽数量结果
领域 话语中的槽实体数 (总数) 槽类型数量 平均F1 (%)
ATP 2 (754), 3 (1 111), 4 (177) 1 53.55
BR 1 (57), 2 (357), 3 (1 069), 4 (320), 5 (178), 6 (80), 7 (12) 2 57.61
GW 1 (358), 2 (914), 3 (673), 4 (155) 3 55.79
PM 1 (521), 2 (862), 3 (531), 4 (185), 5 (1)
RB 2 (158), 2 (611), 4 (880), 5 (400), 6 (7)
SCW 1 (516), 2,(1 538)
FSE 1 (436), 2 (542), 3 (637), 4 (99), 5 (6)
TOP 0 (146), 1 (101), 2 (172), 3 (59), 4 (16), 5 (6)
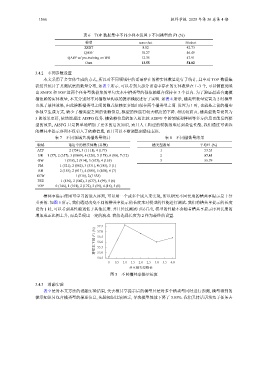
槽共享提示使用可学习的嵌入序列, 可以用一个或多个嵌入来实现, 所以研究不同长度的槽共享提示是十分
重要的. 如图 5 所示, 我们通过改变不同的槽共享提示的长度来对模型的性能进行测试. 我们将槽共享提示的长度
设为 1 时, 可以看到其性能远低于其他长度. 并且经过测试可以看出, 模型的性能不会随着槽共享提示序列长度的
增加成正比例上升, 而是呈现出一定的波动. 我们选择长度为 2 作为最终的设置.
57.5
零样本下的 F1 (%) 56.5
57.0
56.0
55.5
55.0
54.5
0 1.0 1.5 2.0 2.5 3.0 3.5 4.0
共享槽类型数量
图 5 不同槽共享提示长度
3.4.3 消融实验
表 9 是对本文方法的消融实验结果, 失去槽共享提示后的模型只是对多个槽类型同时进行预测, 模型得到的
提示知识只包含槽类型的描述信息, 先验知识比较匮乏, 导致模型性能下降了 3.05%. 我们又将话语填充子任务去