
Page 159 - 《软件学报》2025年第4期
P. 159
王泽 等: 基于槽依赖建模的跨领域槽填充方法 1565
AISFG. 我们复现了对话状态跟踪的一个生成模型 T5DST [24] , 该方法考虑了不同形式的槽类型描述作为 prompt.
实验结果足以证明本文策略的有效性.
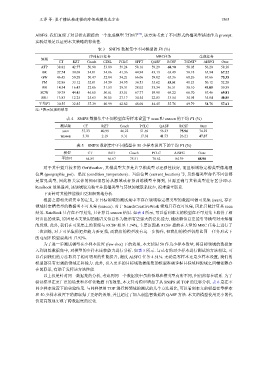
表 3 SNIPS 数据集中不同模型的 F1 (%)
序列标注任务 MRC任务 生成任务
领域
CT RZT Coach CZSL PCLC SPPT QASF RCSF T5DST* AISFG Ours
ATP 38.82 42.77 50.90 53.89 59.24 58.16 59.29 68.70 58.05 56.20 58.36
BR 27.54 30.68 34.01 34.06 41.36 44.94 43.13 63.49 50.18 65.94 67.22
GW 46.45 50.28 50.47 52.04 54.21 66.06 59.02 65.36 68.26 67.66 75.35
PM 32.86 33.12 32.01 34.59 34.95 36.53 33.62 53.51 41.23 50.12 52.28
RB 14.54 16.43 22.06 31.53 29.31 28.02 33.34 36.51 30.10 41.05 39.39
SCW 39.79 44.45 46.65 50.61 53.51 67.77 59.90 69.22 66.70 67.46 69.81
SSE 13.83 12.25 25.63 30.05 27.17 34.54 22.83 33.54 34.01 35.04 40.85
平均F1 30.55 32.85 37.39 40.99 42.82 48.00 44.45 55.76 49.79 54.78 57.61
注: *表示复现的结果
入到训练数据集中, 对模型的少样本迁移能力进行分析. 如表
表 4 SNIPS 数据集中不同模型在零样本设置下 seen 和 unseen 的平均 F1 (%)
测试集 CT RZT Coach PCLC QASF RCSF Ours
seen 37.23 40.99 46.22 51.69 56.23 75.96 74.22
unseen 3.38 2.19 9.31 17.38 41.73 26.21 47.37
表 5 SNIPS 数据集中不同模型在 50 少样本设置下的平均 F1 (%)
模型 CT RZT Coach PCLC AISFG Ours
平均F1 64.85 66.67 75.51 78.62 84.39 88.90
对于其中提升较多的 GetWeather, 其槽类型大多是共享槽类型可迁移性较好, 而且领域特定槽类型像地理
位置 (geographic_poi)、温度 (condition_temperature)、当前位置 (current_location) 等, 虽然槽类型命名不同但都
是常见类型, 因此相关实体的知识很容易从源域或者预训练模型中得到, 只需正确与其他类型进行区分即可.
RateBook 效果最差, 该领域较为独立并且槽类型与其他领域联系较少, 很难建立联系.
下面针对其他性能做出更加细致地分析.
根据之前相关研究中的定义, 在目标领域的测试集中不存在领域特定槽类型的数据叫做可见集 (seen), 存在
领域特定槽类型的数据叫不可见集 (unseen). 对于 SearchCreativeWork 领域只存在可见集, 因此只能计算其 seen
结果. RateBook 只存在不可见集, 只计算其 unseen 结果. 如表 4 所示, 可以看到本文的模型在不可见集上取得了相
对出色的效果, 原因是本文采用的槽语义信息作为提示有更强大的泛化能力, 槽依赖信息更能引导模型对未知槽
的发现. 此外, 我们在可见集上的表现与 RCSF 相差 1.74%, 主要原因是 RCSF 提前在大量的 MRC 任务上进行了
二次训练, 对于可见集的把控能力要更强, 而我们的模型没有这一步操作, 但我们的模型仍然比同一任务形式下
的 QASF 模型要高出 17.92%.
为了进一步测试模型在少样本设置 (few-shot) 下的效果, 本文使用 50 作为少样本数量, 将目标领域的数据加
5 所示. 与已有的对少样本进行测试的方法相比, 可
以看到我们的方法取得了相对明显的性能提升, 超过 AISFG 任务 4.51%. 无论是零样本还是少样本设置, 我们的
模型都具有更强的领域迁移能力. 此外, 引入更多的目标域数据能帮助模型准确掌握目标域和源域之间槽依赖存
在的联系, 有助于发挥该方法性能.
以上仅是针对同一数据集的分析, 考虑到同一个数据集中虽然领域和槽类型有所不同, 但仍然存在联系. 为了
验证模型在更广泛的场景和多样化数据下的效果, 本文针对模型增加了从 SNIPS 到 TOP 的迁移分析. 表 6 是在不
同少样本设置下的实验结果. 与同样使用 TOP 进行跨领域的测试的几个方法相比, 可以看到本文的模型在零样本
和 50 少样本设置下的都取得了更好的效果, 并且超过了加入弱监督数据的 QASF 方法. 本文的模型使用更小的代
价更高效地实现了跨数据集的泛化.