
Page 446 - 《软件学报》2024年第6期
P. 446
3022 软件学报 2024 年第 35 卷第 6 期
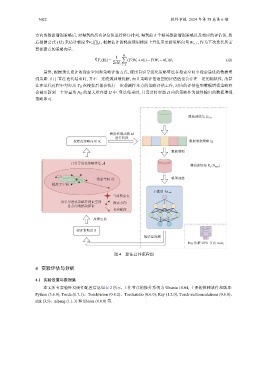
方向的数据增强策略后, 对得到的所有评估值进行降序排列, 得到前 b 个精英数据增强策略以及相应的评估值, 然
ˆ
后根据公式 (12) 来估计梯度 ∇F v ( ∏ t ) , 根据估计的梯度使用梯度上升法来更新策略向量 W t+1 , 作为下次迭代所需
要探索点的策略向量.
1 N s ∑
ˆ
∇F v (Π t ) = (F(W t +νδ i )− F(W t −νδ i ))δ i (12)
2νN s
i=1
最终, 根据预先设计的搜索空间和策略评估方式, 使用自引导进化策略算法在搜索空间中搜索最优的数据增
强策略. 由于算法迭代结束时, 并不一定收敛到最优解, 而且策略评估返回的评估值也会存在一定的随机性, 故算
法在迭代过程中每经历 T U 次搜索后都会执行一次观测样本点的策略评估工作, 对应的评估值和数据增强策略将
会被更新到一个容量为 N H 的最大堆容器 H 中. 算法结束时, 只需要将容器 H 内的策略作为最终输出的数据增强
策略即可.
原始训练集 D train
映射转换函数 M
进行转换
探索点策略向量 W t 数据增强策略 Π t
数据增强
自引导进化策略算法
增强训练集 Π t (D train )
搜索空间 模型训练
梯度子空间
子模型 sub
当前搜索点
自引导进化策略在搜索空间 探索方向
各方向的扰动探索
真实梯度
反馈更新
验证集精度 R
验证集预测
Ray 集群 GPU 节点 node i
图 4 算法总体流程图
4 实验评估与分析
4.1 实验设置与数据集
本文所有实验环境硬件配置信息如表 2 所示, 工作节点的操作系统为 Ubuntu 18.04, 主要的依赖软件和版本:
Python (3.6.8), Torch (1.7.1)、Torchvision (0.8.2)、Torchaudio (0.6.0), Ray (1.2.0), Torch-audiomentations (0.6.0)、
nltk (3.5)、nlpaug (1.1.3) 和 librosa (0.8.0) 等.