
Page 448 - 《软件学报》2024年第6期
P. 448
3024 软件学报 2024 年第 35 卷第 6 期
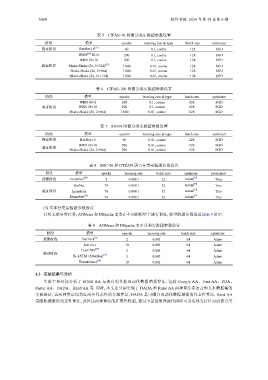
表 5 CIFAR-10 图像分类实验超参数设置
阶段 模型 epochs learning rate & type batch size optimizer
搜索阶段 ResNet-18 [25] 60 0.1, cosine 128 SGD
WRN [26] 40×2 200 0.1, cosine 128 SGD
WRN 28×10 200 0.1, cosine 128 SGD
验证阶段 Shake-Shake (26, 2×32d) [27] 1 800 0.01, cosine 128 SGD
Shake-Shake (26, 2×96d) 1 800 0.01, cosine 128 SGD
Shake-Shake (26, 2×112d) 1 800 0.01, cosine 128 SGD
表 6 CIFAR-100 图像分类实验超参数设置
阶段 模型 epochs learning rate & type batch size optimizer
WRN 40×2 200 0.1, cosine 128 SGD
验证阶段 WRN 28×10 200 0.1, cosine 128 SGD
Shake-Shake (26, 2×96d) 1 800 0.01, cosine 128 SGD
表 7 SVHN 图像分类实验超参数设置
阶段 模型 epochs learning rate & type batch size optimizer
搜索阶段 ResNet-18 60 0.01, cosine 128 SGD
WRN 28×10 200 0.01, cosine 128 SGD
验证阶段
Shake-Shake (26, 2×96d) 200 0.01, cosine 128 SGD
表 8 ESC-50 和 GTZAN 语音分类实验超参数设置
阶段 模型 epochs learning rate batch size optimizer pretrained
搜索阶段 Inception [28] 5 0.000 1 32 Adam [29] True
[29]
Adam
ResNet 70 5
32
0.000 1
True
验证阶段 Inception 70 0.000 1 32 Adam [29] True
DenseNet [30] 70 0.000 1 32 Adam [29] True
(3) 文本分类实验超参数设置
针对文本分类任务, AGNews 和 DBpedia 需要在不同的模型上进行训练, 模型的超参数设置如表 9 所示.
表 9 AGNews 和 DBpedia 文本分类实验超参数设置
阶段 模型 epochs learning rate batch size optimizer
搜索阶段 fastText [31] 2 0.001 64 Adam
fastText 10 0.001 64 Adam
TextCNN [32] 0.001 64 Adam
验证阶段 [33]
Bi-LSTM+Attention 5 0.001 64 Adam
Transformer [34] 10 0.001 64 Adam
4.3 实验结果与分析
实验主要对比分析了 SGES AA 与现有的其他自动化数据增强算法, 包括 Google AA、Fast AA、PBA、
Faster AA、DADA、Rand AA 等. 同时, 本文还分别实现了 DADA 和 Rand AA 两种算法在语音和文本数据集的
实验验证, 这两种算法均为近两年代表性的开源算法, DADA 是可微分自动化数据增强的代表性算法, Rand AA
是随机搜索的代表性算法, 此外这两种算法的扩展性较强, 通过少量的修改源代码即可灵活地支持针对语音分类