
Page 350 - 《软件学报》2024年第6期
P. 350
2926 软件学报 2024 年第 35 卷第 6 期
实体类型识别任务, 并显式注入了相对位置信息. 上述的这些方法在识别嵌套实体的过程中, 都没有考虑在医疗文
本特定领域下实体与实体之间的嵌套存在着不同的类别限制. 本文所提出的 MTS-NER 系统基于改进后的多头选
择机制, 将从实际中文医疗文本数据的分析得到的实体之间的嵌套过滤规则融合进对实体的识别过程, 进一步提
升了模型对中文医疗文本中的实体识别效果.
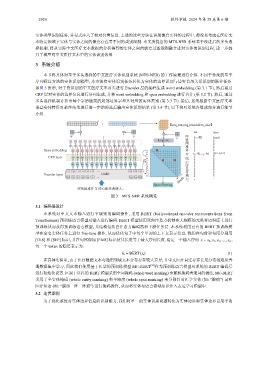
3 系统介绍
本节将具体对基于多头选择的中文医疗实体识别系统 (MTS-NER) 的工作原理进行介绍. 不同于传统的基于
序列标注方法的实体识别模型, 本方法将实体识别任务转化为实体的边界识别与边界首尾关系识别的联合任务.
如图 3 所示, 对于待识别的中文医疗文本首先进行 Encoder 层的编码生成 word embedding (第 3.1 节), 然后通过
CRF 层对实体的边界信息进行序列生成, 并将 word embedding 和 span embedding 进行合并 (第 3.2 节). 然后, 通过
多头选择机制计算出每个字所链接的尾部边界字和其对应的实体类别 (第 3.3 节). 最后, 系统根据中文医疗文本
嵌套实体特征对最终结果进行进一步的筛选后输出实体识别结果 (第 3.4 节). 以下将对系统各组成部分进行细节
介绍.
h i = BERT(x i )
T
+ }seq_len,seq_len,hidden_size~
tail label
W U [x 3 : 难] [sym]
V
Logistic
Span embedding x 0
x 1 [x 6 : 线, x 12 : 大] [pro, sym]
x 2
CRF layer x 3 x 4
x 5
x 6
x 7
x 8
x 9
x 10
x 11
Encoder layer BERT x 12
x 13
labels
Span filtering
呼吸困难伴 X 线心影显著增大。
图 3 MTS-NER 系统概览
3.1 编码层设计
本系统对中文文本输入进行字级别的编码操作, 采用 BERT (bidirectional encoder representations from
Transformers) 预训练语言模型对输入进行编码. BERT 模型使用双向注意力机制在大规模的无监督语料库上进行
预训练从而获得预训练语言模型, 其结构包括自注意力编码器和下游任务层. 本系统利用已有的 BERT 预训练模
型在命名实体任务上进行 fine-tune 操作, 从而优化句子中每个单词的上下文表示信息. 我们在句首和句尾分别用
[CLS] 和 [SEP] 标记, 并在句尾添加 [PAD] 标记使其长度等于最大序列长度. 给定一个输入序列 x = x 0 , x 1 , x 2 ,..., x n ,
每一个 token 的隐层表示为:
(1)
在具体实验中, 由于医疗数据文本与通用领域文本分布存在较大差异, 且中文医疗词汇存在长尾分布很难从普
通数据集中学习, 因此我们使用基于医学的预训练模型 MC-BERT [34] 作为预训练语言模型对系统的 BERT 编码层
进行初始化设置. 区别于以往的 BERT 模型采用全词掩码 (whole word masking) 来随机掩码普通词的做法, MC-BERT
采用了全实体掩码 (whole entity masking) 和全跨度 (whole span masking) 来分别针对医学实体 (如: “腹痛”) 词和
医疗短语 (如: “腹部一阵一阵痛”) 进行掩码操作, 从而将实体与语言领域知识注入表达学习模型中.
3.2 边界识别
为了强化系统对实体边界信息的识别能力, 我们将单一的实体识别问题转化为实体边界和实体边界首尾字的