
Page 234 - 《软件学报》2024年第6期
P. 234
2810 软件学报 2024 年第 35 卷第 6 期
C-SVMXGBoost 相对于其他模型, 精度最高, 处于 90%–95% 之间, 但随着样本数量的增加, 其自身提升程度不明
显, 这再一次说明该链式模型在小样本测试数据上即可达到较高精度.
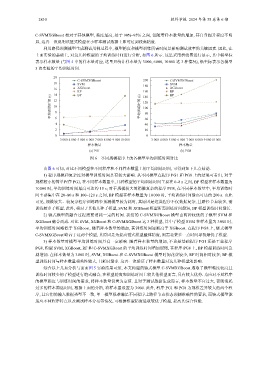
利用路径预测模型生成测试用例过程中, 模型精度和模型训练所需时间是影响测试效率的关键因素. 因此, 在
上面实验的基础上, 对这几种模型的平均训练时间进行分析, 如图 6 所示. 这里采用折线图进行展示, 其中横坐标
表示样本数量 (与图 5 中的样本量对应, 这里只统计样本量为 3 000, 6 000, 10 000 这 3 种情况), 纵坐标表示各模型
5 次实验的平均训练时间.
20
C-SVMXGBoost 200 C-SVMXGBoost
18
SVM 180 SVM
16 XGBoost XGBoost
RF 160 RF
14
BP
BP
平均训练时间 (s) 12 8 平均训练时间 (s) 120
140
10
100
80
时, SVM, XGBoost 和
4 6 60
40
2 20
0 0
3 000 4 000 5 000 6 000 7 000 8 000 9 00010 000 3 000 4 000 5 000 6 000 7 000 8 000 9 00010 000
样本数量 样本数量
(a) PG1 (b) PG8
图 6 不同规模程序上的各模型平均训练时间对比
由图 6 可知, 对比不同模型在不同程序和不同样本数量上的平均训练时间, 可得到如下几点结论.
1) 程序规模和复杂度对模型训练时间具有较大影响. 从不同模型在程序 PG1 和 PG8 上的结果可看出, 对于
规模较小的简单程序 PG1, 在不同样本数量中, 几种模型的平均训练时间主要在 0–8 s 之间, BP 模型在样本数量为
10 000 时, 平均训练时间最高可达约 15 s; 对于规模较大的稍微复杂的程序 PG8, 在不同样本数量中, 平均训练时
间主要集中在 20–80 s 和 100–120 s 之间, BP 模型在样本数量为 10 000 时, 平均训练时间最高可达约 200 s. 由此
可见, 规模较大、较复杂程序训练路径预测模型较为耗时, 其原因是这类程序不仅数据复杂, 且路径节点较多, 需
训练较多子模型. 此外, 相对于其他几种子模型, SVM 和 XGBoost 模型所需训练时间最短, BP 模型训练时间最长.
2) 链式模型的融合过程需要消耗一定的时间. 我们的 C-SVMXGBoost 模型由两种较优的子模型 SVM 和
XGBoost 融合而成. 对比 SVM, XGBoost 和 C-SVMXGBoost 这 3 种模型, 其中子模型 SVM 在样本量为 3 000 时,
平均训练时间略低于 XGBoost, 随着样本数量的增加, 其训练时间逐渐高于 XGBoost. 在程序 PG8 上, 链式模型
C-SVMXGBoost 略高于这两个模型, 其原因是为提高链式模型整体精度, 则需花费多一点时间寻找最优子模型.
3) 样本数量对模型平均训练时间具有一定影响. 随着样本数量的增加, 不论是基础程序 PG1 还是工业程序
PG8, 模型 SVM, XGBoost, RF 和 C-SVMXGBoost 的平均训练时间增加缓慢, 在程序 PG8 上, BP 模型训练时间急
剧增加. 在样本数量为 3 000 C-SVMXGBoost 模型时间花费较少, RF 时间相对较多; BP 模
型训练时间与样本数量相关性较大, 且耗时最多. 这再一次验证了样本数量对这几种模型的影响.
综合以上几点分析与前面图 5 实验结果可知, 本文构建的链式模型 C-SVMXGBoost 选取了模型精度较高且
训练时间较少的子模型进行链式融合, 在模型精度和训练时间上较其他模型而言, 具有较大优势. 为应对不同程序
的模型精度与训练时间的需求, 将样本数量设置为定值. 且对于测试数据生成而言, 样本数量不宜过大, 否则消耗
过多的样本筛选时间, 根据上面的分析, 将样本量设置为 3 000. 此外, 程序 PG1 和 PG8 为规模差异较大的两个程
序, 且它们的输入数据类型不一致, 单一模型很难满足不同程序上路径节点状态预测准确性的要求, 而链式模型能
适应不同程序特点以及测试样本分布等情况, 可根据模型精度选取较优子模型, 提高其综合性能.