
Page 232 - 《软件学报》2024年第6期
P. 232
2808 软件学报 2024 年第 35 卷第 6 期
100 100
98 98
96 96
精度 (%) 94 精度 (%) 94
SVM SVM
92 XGBoost 92 XGBoost
RF RF
BP BP
90 90
1 000 2 000 3 000 4 000 1 000 2 000 3 000 4 000
样本数量 样本数量
2 000
(a) 较小规模程序 PG1 上各子模型分类精度对比 (b) 较大规模程序 PG8 上各子模型分类精度对比
8 160
140
6 120
训练时间 (s) 4 SVM 训练时间 (s) 100 SVM
80
XGBoost
RF
XGBoost
RF 60 BP
2 BP 40
20
0 0
1 000 2 000 3 000 4 000 1 000 2 000 3 000 4 000
样本数量 样本数量
(c) 较小规模程序 PG1 上各子模型训练时间对比 (d) 较大规模程序 PG8 上各子模型训练时间对比
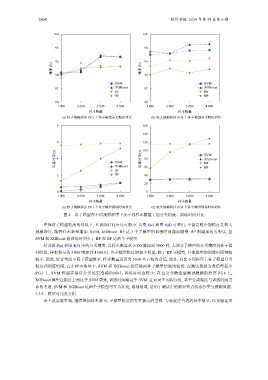
图 4 各子模型在不同规模程序下及不同样本数量上的分类精度、训练时间对比
在保证子模型精度的情况下, 其训练时间应尽可能少. 由图 4(c) 和图 4(d) 可看出, 不论是较小规模还是较大
规模程序, 随着样本数量增加, SVM, XGBoost, RF 这 3 个子模型的训练时间增加缓慢, BP 则增加较为明显, 且
SVM 和 XGBoost 的训练时间少于 RF 和 BP 这两个子模型.
结合图 4(a) 和图 4(b) 中的分类精度, 当样本数量从 增加到 3 000 时, 大部分子模型的分类精度仍处于提
升阶段, 样本数量从 3 000 增加到 4 000 时, 各子模型精度增加不明显, 除了 BP 子模型, 其他模型的训练时间增幅
较小. 因此, 综合考虑不同子模型效率, 样本数量设置为 3 000 左右较为合适. 此外, 对比不同程序上各子模型分类
精度和训练时间, 在小样本数量上, SVM 和 XGBoost 较其他两种子模型结果均较优. 在测试数据为数值型程序
PG1 上, SVM 模型在保证分类结果准确的同时, 训练时间也较少; 在包含非数值型测试数据的程序 PG8 上,
XGBoost 模型在精度上相比于 SVM 更优, 训练时间略高于 SVM. 在面对不同程序时, 基于分类精度与训练时间方
面的考虑, SVM 和 XGBoost 这两个子模型可互为补充, 相辅相成, 适用于测试中的路径节点状态分类与预测问题.
5.3.2 模型对比及分析
由上述实验可知, 继续增加样本数量, 子模型精度仍有可提高的空间. 为选取更合适的样本数量, 以及验证本