
Page 233 - 《软件学报》2024年第6期
P. 233
钱忠胜 等: 结合 SVM 与 XGBoost 的链式多路径覆盖测试用例生成 2809
文构建的链式模型 (即 C-SVMXGBoost) 是否比其他模型在精度与时间方面更有优势, 选取的实验程序与上一节
一致, 并设置更多样本数量, 分别为 3 000, 6 000, 10 000, 就模型分类精度进一步展开对比. 每组实验分别重复 5 次,
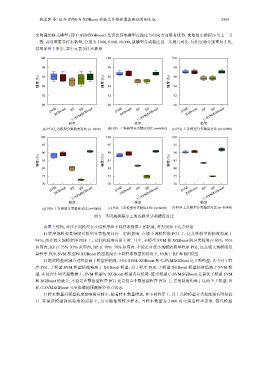
结果如图 5 所示, 其中 n 表示样本数量.
100 100 100
98 98 98
精度 (%) 96 精度 (%) 96 精度 (%) 96
94
94
94
92 92 92
90 90 90
BP
BP
SVM XGBoost RF C-SVMXGBoost SVM XGBoost RF C-SVMXGBoost SVM XGBoost RF C-SVMXGBoost
BP
2) 链式模型的融合过程提高了模型的精度. 对比
模型 模型 模型
(a) PG1上各模型分类精度对比 (n=3000) (b) PG1 上各模型分类精度对比 (n=6000) (c) PG1 上各模型分类精度对比 (n=10000)
100 100 100
95 95 95
90 90 90
精度 (%) 85 精度 (%) 85 精度 (%) 85
80 80 80
75 75 75
70 70 70
BP
SVM XGBoost RF C-SVMXGBoost SVM XGBoost RF C-SVMXGBoost SVM XGBoost RF C-SVMXGBoost
BP
BP
模型 模型 模型
(d) PG8 上各模型分类精度对比 (n=3000) (e) PG8 上各模型分类精度对比 (n=6000) (f) PG8 上各模型分类精度对比 (n=10000)
图 5 不同规模程序上的各模型分类精度对比
由图 5 可知, 对比不同模型在不同程序和不同样本数量上的精度, 可得到如下几点结论.
1) 程序规模和复杂度对模型分类精度具有一定的影响. 在较小规模程序 PG1 上, 这几种模型的精度均高于
94%, 而在较大规模程序 PG8 上, 它们的精度有所下降. 其中, 子模型 SVM 和 XGBoost 的分类精度在 85%–95%
范围内; RF 在 75%–85% 范围内; BP 在 70%–78% 范围内. 不论是对较小规模的简单程序 PG1, 还是较大规模的复
杂程序 PG8, SVM 模型和 XGBoost 模型精度在不同样本数量的情况下, 均高于 RF 和 BP 模型.
SVM, XGBoost 和 C-SVMXGBoost 这 3 种模型, 其中对于程
序 PG1, 子模型 SVM 模型精度略高于 XGBoost 模型; 对于程序 PG8, 子模型 XGBoost 模型精度值高于 SVM 模
型. 在处理不同类型数据上, SVM 模型与 XGBoost 模型各有优势. 链式模型 C-SVMXGBoost 是最优子模型 SVM
和 XGBoost 的融合, 不论是在数值型程序 PG1 还是包含非数值型程序 PG8 上, 它的精度均高于这两个子模型, 因
此 C-SVMXGBoost 可更准确地预测路径节点状态.
3) 样本数量对模型精度影响相对较小. 随着样本数量增加, 在不同程序上, 以上几种模型分类精度没有明显提
升. 在保证模型训练精度的前提下, 尽可能使用较少样本, 当样本数量为 3 000 时可满足样本需求. 链式模型