
Page 306 - 《软件学报》2021年第12期
P. 306
3970 Journal of Software 软件学报 Vol.32, No.12, December 2021
4.4 放化疗疗效预测实验对比
本文基于随机森林算法预测放化疗不敏感的宫颈鳞癌患者.实验将疗效预测问题归结为分类问题(完全缓
解或不完全缓解两类).因此,为了验证本文方法的有效性,加入 Inception-ResNet-v2 算法以及 Inception-v4 [40] 算
法作为预测疗效效果对比模型.通过多种实验验证算法的有效性,实验包括决策树数量实验、决策树剪枝策略
实验以及不同预测算法对比实验.实验所用 AUC 取值范围是 0.5~1,0.5 对应随机猜想模型,1 对应理想模型.
4.4.1 决策树数量实验
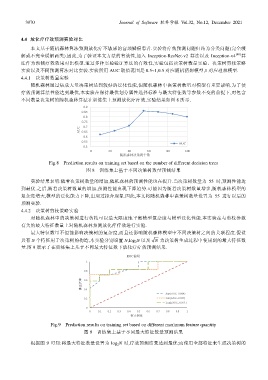
随机森林通过集成大量决策树达到较好的泛化性能,但随机森林中决策树数量对模型有重要影响.为了使
疗效预测算法性能达到最优,本实验在保持最优划分属性选择标准与最大特征数等参数不变的前提下,对包含
不同数量决策树的随机森林算法在训练集上预测放化疗疗效,实验结果如图 8 所示.
0.9
0.85
0.8
0.75
0.7
AUC 0.65
0.6
0.55
AUC
0.5
0 20 40 60 80 100
随机森林决策树个数
Fig.8 Prediction results on training set based on the number of different decision trees
图 8 训练集上基于不同决策树数量预测结果
实验结果表明:随着决策树数量的增加,随机森林的预测性能也在提升.当决策树数量为 55 时,预测性能达
到最优.之后,随着决策树数量的增加,预测性能出现下降趋势.可能因为随着决策树数量增多,随机森林模型的
复杂度增大,模型的泛化能力下降,出现过拟合现象.因此,本文将随机森林中决策树数量设置为 55 进行以后的
预测实验.
4.4.2 决策树剪枝策略实验
对随机森林中的决策树进行剪枝可以最大限度地平衡模型复杂度与模型泛化性能.本实验在与剪枝参数
有关的最大特征数量上对随机森林预测放化疗疗效进行实验.
最大特征数量不但能影响决策树的复杂度,而且还影响随机森林模型中不同决策树之间的关联程度.假设
共有 N 个特征用于决策树的构造,本实验分别设置 N,log 2 N 以及 N 为决策树生成过程中使用到的最大特征数
量.图 9 展示了在训练集上基于不同最大特征数下放化疗疗效预测结果.
ROC曲线
1
0.8
真正例率 0.6
0.4
Sqrt(AUC=0.864)
0.2 Full(AUC=0.857)
Log2(AUC=0.871)
0
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
假正例率
Fig.9 Prediction results on training set based on different maximum feature quantity
图 9 训练集上基于不同最大特征数量预测结果
根据图 9 可知:将最大特征数量设置为 log 2 N 时,疗效预测结果达到最优;而使用全部特征来生成决策树的