
Page 234 - 《软件学报》2021年第12期
P. 234
3898 Journal of Software 软件学报 Vol.32, No.12, December 2021
每个簇中离代表点最近的另外 9 幅图像,规模不足 10 的簇则选取其全部图像)作为代表图像,并考虑形成约
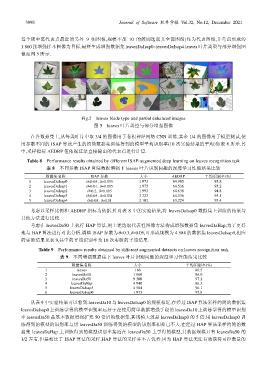
1 860 张增强样本图像为目标,最终生成增强数据集 leavesDaIsap0~leavesDaIsap4.leaves 叶片类型与部分增强图
像如图 5 所示.
Fig.5 leaves blade type and partial enhanced images
图 5 leaves 叶片类型与部分增强图像
在各数据集上,从每类叶片中取 3/4 的图像用于卷积神经网络 CNN 训练,其余 1/4 的图像用于模型测试,使
用参数不同的 ISAP 算法产生的约简数据集训练得到的模型平均识别率(10 次实验结果的平均)如表 8 所示.其
中,采样指标 AEDRP 值依据算法直接输出的代表点进行计算.
Table 8 Performance results obtained by different ISAP-augmented deep learning on leaves recognition task
表 8 不同参数 ISAP 算法数据增强下 leaves 叶片识别问题的深度学习性能结果比较
数据集名称 ISAP 参数 大小 AEDRP 平均识别率(%)
1 leavesDaIsap0 θ=0.05, δ=0.005 1 973 64.985 95.8
2 leavesDaIsap1 θ=0.01, δ=0.005 1 975 64.536 95.2
3 leavesDaIsap2 θ=0.2, δ=0.005 1 993 64.638 94.8
4 leavesDaIsap3 θ=0.05, δ=0.001 2 233 64.536 95.1
5 leavesDaIsap4 θ=0.05, δ=0.01 2 102 63.224 95.4
考虑以采样比例和 AEDRP 指标为依据,针对表 8 中的实验结果,将 leavesDaIsap0 数据集上训练的结果与
其他方法进行比较.
考虑在 leavesDa50 上执行 HAP 算法,用上述选取代表性图像方法构成增强数据集 leavesDaHap;为了更好
地与 HAP 算法进行对比分析,调整 ISAP 参数为θ=0.3,δ=0.05,可形成规模为 4 584 的数据集 leavesDaIsap5,相应
的实验结果见表 9,其中的平均识别率为 10 次实验的平均结果.
Table 9 Performance results obtained by different augmented datasets on leaves recognition task
表 9 不同增强数据集下 leaves 叶片识别问题的深度学习性能结果比较
数据集名称 大小 平均识别率(%)
1 leaves 186 80.5
2 leavesDa10 1 860 86.0
3 leavesDa50 9 300 97.2
4 leavesDaHap 4 940 96.3
5 leavesDaIsap5 4 584 96.1
6 leavesDaIsap0 1 973 95.8
从表 9 中实验结果可以看到:leavesDa10 与 leavesDaIsap0 的规模相近,在经过 ISAP 算法采样约简的数据集
leavesDaIsap0 上训练学得的模型识别率远好于在使用简单数据增强手段的 leavesDa10 上训练学得的模型识别
率.leavesDa50 是基本数据增强扩充 50 倍后的数据集,其规模大致是 leavesDaIsap0 的 5 倍.用 leavesDaIsap0 训
练得到的模型的识别率与用 leavesDa50 训练得到的模型的识别率相差已不大.在经过 HAP 算法采样约简的数
据集 leavesDaHap 上训练得到的模型识别率接近在 leavesDa50 上学得的模型,其数据规模只有 leavesDa50 的
1/2 左右.但是相比于 ISAP 算法的采样,HAP 算法的采样并不占优势.因为 HAP 算法无法有效获得可控数量的