
Page 233 - 《软件学报》2021年第12期
P. 233
陈晓琪 等:基于动态赋权近邻传播的数据增量采样方法 3897
实验结果见表 7.从表中结果可以看到:综合考虑代表性图像的平均距离、距离方差、综合覆盖度以及时间
效率,ISAP 算法具有较为明显的优势.标准 AP 算法在各方面都不占优势;IAPNA 方法在数据集规模较大时时间
耗费过大;而 HAP 算法得到的代表图像之间的平均距离较大,但是代表图像间距离的方差明显超过另外 3 种方
法,其代表图像间的距离分布不平滑.
Table 7 Performance results obtained by serval compared methods
on representational image selection problem
表 7 对比方法在代表性图像选择实验上的性能结果
CarLogo ILSVARC50
评价指标
AP HAP IAPNA ISAP AP HAP IAPNA ISAP
类数 41 12 19 18 167 57 36 46
AEDRP 0.79 0.77 0.79 0.81 108 108 91 91
VRP 0.02 0.03 0.02 0.01 458 937 161 146
CCR 0.84 0.94 0.93 0.94 0.93 0.97 0.98 0.97
耗时(s) 0.05 0.79 0.49 0.27 10.3 15.2 121 6.20
ILSVARC100 ILSVARC150
评价指标
AP HAP IAPNA ISAP AP HAP IAPNA ISAP
类数 304 90 107 104 449 180 − 178
AEDRP 107 119 100 96 109 122 − 100
VRP 477 840 252 171 541 953 − 187
CCR 0.94 0.98 0.97 0.98 0.94 0.97 − 0.97
耗时(s) 51.3 191 1 303 26.5 155 691 − 58.4
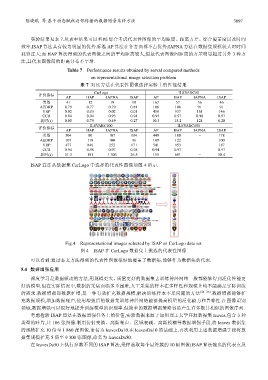
ISAP 算法从数据集 CarLogo 中选择的代表性图像如图 4 所示.
Fig.4 Representational images selected by ISAP on CarLogo data set
图 4 ISAP 在 CarLogo 数据集上挑选的代表性图像
可以看到:通过本文方法得到的代表性图像很好地覆盖了数据集,能够作为数据集的代表.
5.4 数据增强应用
深度学习是数据驱动的方法,用规模更大、质量更好的数据集去训练神经网络一般都能够得到泛化性能更
好的模型.但在实际情况中,数据的采集面临多重困难,人工采集的样本在多样性和规模上均不能满足实际训练
的需求.数据增强即数据扩增,是一种有效扩充数据规模,解决训练样本不足问题的方法 [24−26] .数据增强能够扩
充数据规模,增加数据噪声,使用增强后的数据集训练神经网络能够提高模型的泛化能力和鲁棒性.在图像识别
领域,数据增强可以很好地提升训练模型的识别率.但简单的数据增强策略容易产生许多极其相似的图像序列.
考虑检验 ISAP 算法在数据增强任务上的价值,实验数据来源于加州理工大学开源数据集 leaves,包含 3 种
类型的叶片,共 186 张图像.利用仿射变换、高斯噪声、区域衰减、高斯模糊等数据增强手段,将 leaves 数据集
的规模扩充 10 倍至 1 860 张图像,命名为 leavesDa10.在 leavesDa10 的基础上,再次利用上述数据增强手段将数
据集规模扩充 5 倍至 9 300 张图像,命名为 leavesDa50.
在 leavesDa50 上执行参数不同的 ISAP 算法,采样选取每个最终簇的 10 幅图像(ISAP 算法输出的代表点及