
Page 100 - 《软件学报》2021年第12期
P. 100
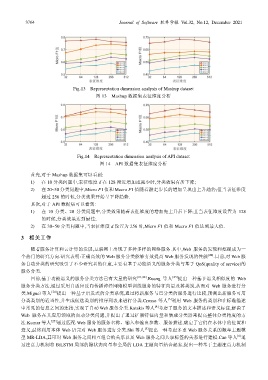
3764 Journal of Software 软件学报 Vol.32, No.12, December 2021
Fig.13 Representation dimension analysis of Mashup dataset
图 13 Mashup 数据集表征维度分析
Fig.14 Representation dimension analysis of API dataset
图 14 API 数据集表征维度分析
首先,对于 Mashup 数据集可以看到:
1) 在 10 分类问题中,表征维度 d 在 128 附近增加或减少时,分类效果有所下降;
2) 在 20~50 分类问题中,Micro F1 值和 Macro F1 值随着游走步长的增加呈现出上升趋势;但当表征维度
超过 256 的时候,分类效果开始呈下降趋势.
其次,对于 API 数据集可以看到:
1) 在 10 分类、20 分类问题中,分类效果随着表征维度的增加先上升后下降;且当表征维度设置为 128
的时候,分类效果达到最佳;
2) 在 30~50 分类问题中,当表征维度 d 设置为 256 时,Micro F1 值和 Macro F1 值达到最大值.
3 相关工作
随着服务计算和云计算的发展,互联网上出现了多种多样的网络服务.其中,Web 服务的发现和挖掘成为一
个热门的研究方向.研究表明:正确高效的 Web 服务分类能够有效提高 Web 服务发现的性能 [20] .目前,对 Web 服
务自动分类的研究吸引了不少研究者的注意,主要有基于功能语义的服务分类与基于 QoS(quality of service)的
服务分类.
目前,基于功能语义的服务分类方法已有大量的研究 [21,22] .Kuang 等人 [23] 提出一种基于语义相似度的 Web
服务分类方法,通过采用自适应反向传播神经网络模型训练服务的特征向量及其类别,从而对 Web 服务进行分
类.Miguel 等人 [24] 提出一种基于启发式的分类系统,通过将新服务与已分类的服务进行比较,预测出新服务可用
[3]
分类类别的适当性,并生成候选类别的排序列表来进行分类.Crosso 等人 利用 Web 服务的类别和在标准描述
[4]
中常见的信息之间的连接,实现了自动 Web 服务分类.Katakis 等人 考虑了服务的文本描述和语义标注,解决了
Web 服务在其应用领域的自动分类问题,并提出了通过扩展特征向量和集成分类器来提高整体分类精度的方
法.Kumar 等人 [25] 通过匹配 Web 服务的服务名称、输入和输出参数、服务描述,确定了它们在本体中的位置和
[5]
意义,最终利用本体 Web 语言对 Web 服务进行分类.Shi 等人 提出一种考虑多重 Web 服务关系的概率主题模
[6]
型 MR-LDA,其可对 Web 服务之间相互组合的关系以及 Web 服务之间共享标签的关系进行建模.Cao 等人 通
过注意力机制将 BiLSTM 局部的隐状态向量和全局的 LDA 主题向量结合起来,提出一种基于主题注意力机制