
Page 91 - 《软件学报》2021年第11期
P. 91
袁敏 等:面向数据特征的人机物融合服务分派方法 3417
情的合理科室,计算出新病情与科室中医生诊疗病例记录摘要的相似度,得到相似度较高的 3 位医生.
(2) 考虑服务匹配度和满意度的方法(CS-MS):选择用户倾向性最高的一组服务提供者.根据分类器得出
新病情的合理科室,计算出病情与该科室中所有医生诊疗摘要的相似度,得到相似度较高的 k 位医生,
从这 k 位医生中选择满意度最高的 3 位医生.
(3) 基于项目相似性的方法(I-S) [40] .即将相似的一组项目的用户打分作为标准,为其他用户推荐预测分高
的项目.在病患就诊场景下,相似的一组项目可以理解为同科室的医生提供的服务,根据历史患者对
医生的评级作为新病患对医生的评级预测,推荐预测值较优的 3 位医生.
(4) 基于用户相似性的方法(U-S) [41,42] .即以与目标用户相似的一组历史用户的打分为依据,根据与目标
用户的相似度作修正打分的权值.计算历史患者的病情与新病患的相似度,并根据历史患者的评级计
算预测分.预测分=病患相似度*评级得分,最终择优选择 3 位医生.
(5) 本文方法:考虑服务匹配度、满意度和成熟度(CSP-MSM).根据分类器得出新病情的合理科室,计算出
病情与该科室中所有医生诊疗摘要的相似度,得到相似度较高的 k 位医生.在这 k 位医生中,结合医院
等级、医生职称和满意度得分,找出最合适的 3 位医生.
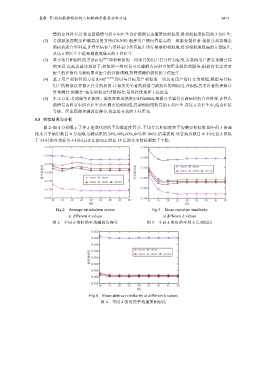
5.5 实验结果与分析
图 2~图 4 分别展示了在 k 值变化时的平均满意度得分、平均专长相似度和平均摘要相似度.图中的 5 条曲
线来自于病患数目 N 分别取为测试集的 20%,40%,60%,80%和 100%.结果表明:尽管病患数目 N 不同,但 k 值低
于 35 时的各指标各不相同且存在波动,k 值在 35 后的各项指标都趋于平稳.
Fig.2 Average satisfaction scores Fig.3 Mean expertise similarity
at different k values at different k values
图 2 不同 k 值时的平均满意度得分 图 3 不同 k 值时的平均专长相似度
Fig.4 Mean abstract similarity at different k values
图 4 不同 k 值时的平均摘要相似度