
Page 230 - 《软件学报》2021年第11期
P. 230
3556 Journal of Software 软件学报 Vol.32, No.11, November 2021
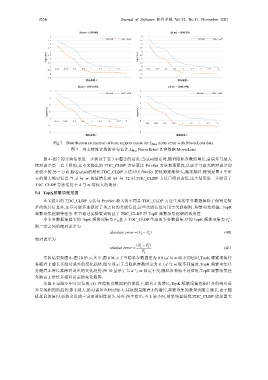
Fig.7 Distribution estimation of item support count for L Max norm error with MovieLens data
图 7 项支持度计数的分布估计,L Max Norm Error-真实数据 MovieLens
图 4~图 7 的实验结果进一步验证了表 3 中蕴含的结论:当(d,m)固定时,随着隐私参数的增长,总误差与最大
绝对误差是一直下降的;且本文提出的 TDC_CLDP 方法要比 PrivSet 方法表现更优,总误差与最大绝对误差均
是较小的.另一方面,随着(d,m)的增长,TDC_CLDP 方法对比 PrivSet 的优势逐渐增大,越来越好.特别是图 4 中所
示的最大绝对误差,当 d 与 m 的值增长到 64 与 32 时,TDC_CLDP 方法已明显占优,这个结果进一步验证了
TDC_CLDP 方法适用于 d 与 m 均较大的场景.
5.4 TopK频繁项集挖掘
本文提出的 TDC_CLDP 方法与 PrivSet 最大的不同是:TDC_CLDP 方法生成的事务数据集除了保留足够
多的统计信息外,还尽可能多地保留了项之间的关联信息,这些关联信息可用于关联规则、频繁项集挖掘、TopK
频繁项集挖掘等任务.本节通过实验重点验证了 TDC_CLDP 对 TopK 频繁项集挖掘的效用性.
令事务数据集真实的 TopK 频繁项集为 F k ,基于 TDC_CLDP 生成的事务数据集 D′的 TopK 频繁项集为 F′ ,
k
则二者之间的绝对误差为
absolute error = | F − F′ k | (40)
k
相对误差为
| F − F | ′
relative error = k k (41)
F k
实验结果如图 8~图 10 所示.其中,图 8 显示了当隐私参数固定为 0.01,d 与 m 取不同值时,TopK 频繁项集任
务随着 k 增长其绝对误差的变化趋势;图 9 显示了当隐私参数固定为 0.1,d 与 m 取不同值时,TopK 频繁项集任
务随着 k 增长其绝对误差的变化趋势;图 10 显示了当 d 与 m 固定不变,隐私参数取不同值时,TopK 频繁项集任
务随着 k 增长其相对误差的变化趋势.
从图 8 与图 9 中可以发现:(1) 在隐私参数固定的前提下,随着 k 的增长,TopK 频繁项集挖掘任务的绝对误
差呈现相同的趋势,即 k 越大,绝对误差也相对较大.其原因是随着 k 的增长,频繁项集的数量也随之增长.由于随
机扰乱的原因,必然会造成一定的效用性损失.另外,图中指出:当 k 较小时,结果明显较优,TDC_CLDP 能保留大