
Page 227 - 《软件学报》2021年第11期
P. 227
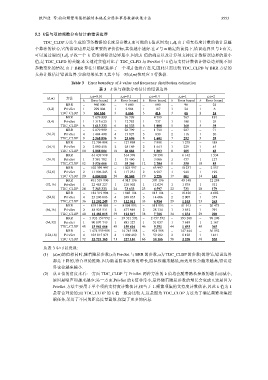
欧阳佳 等:面向频繁项集挖掘的本地差分隐私事务数据收集方法 3553
5.2 k值与项的频数分布估计的错误边界
TDC_CLDP 方法生成的事务数据的长度是参数 k,而可能的 k 值范围为[1,d],由于项支持度计数的估计是整
个算法的核心,它的错误边界是最重要的评价指标,其值越小越好.在 d 与 m 确定的前提下,错误边界只与 k 有关,
可以通过遍历[1,d],寻找一个 k 值使得错误边界最小.因此,k 值的确定以及计算项支持度计数错误边界的最小
值,是 TDC_CLPD 的关键.本文通过实验对比了 TDC_CLPD 与 PrivSet 中 k 值与支持计数估计错误边界随不同
参数变化的情况.由于 BRR 算法只随机选择了一个项,k 值没有意义,因此只需比较 TDC_CLPD 与 BRR 方法的
支持计数估计错误边界.实验结果见表 3,其中每一对(d,m)值对应 3 行数据.
Table 3 Error boundary of k value and frequency distribution estimation
表 3 k 值与频数分布估计的错误边界
ε,α=0.01 ε,α=0.1 ε,α=0.4 ε,α=1 ε,α=2
(d,m) 方法
k Error bound k Error bound k Error bound k Error bound k Error bound
BRR − 960 000 − 9 600 − 600 − 96 − 24
(4,2) PrivSet 1 299 004 1 2 904 1 167 1 24 1 6
TDC_CLDP 3 666 666 3 6 666 3 416 3 66 2 16
BRR − 7 679 999 − 76 799 − 4 799 − 767 − 191
(8,4) PrivSet 1 1 315 623 1 12 783 1 737 1 108 1 29
TDC_CLDP 6 1 613 333 6 16 133 6 1 008 5 160 5 39
BRR − 2 879 999 − 28 799 − 1 799 − 287 − 71
(16,2) PrivSet 4 1 404 490 4 13 827 3 830 2 116 1 20
TDC_CLDP 9 2 568 896 9 25 696 8 1 601 7 252 5 59
BRR − 12 799 998 − 127 998 − 7 998 − 1 278 − 318
(16,4) PrivSet 2 2 880 450 2 28 169 2 1 663 1 229 1 45
TDC_CLDP 10 2 888 004 10 28 884 9 1 803 8 285 7 68
BRR − 61 439 998 − 614 398 − 38 398 − 6 142 − 1 534
(16,8) PrivSet 1 5 501 702 1 53 460 1 3 086 1 457 1 127
TDC_CLDP 12 3 526 666 12 35 266 12 2 204 11 350 10 85
BRR − 102 399 997 − 1 023 997 − 63 997 − 10 237 − 2 557
(32,8) PrivSet 2 11 996 243 2 117 231 2 6 907 1 948 1 192
TDC_CLDP 20 6 084 008 20 60 848 19 3 796 17 601 14 145
BRR − 491 519 996 − 4 915 196 − 307 196 − 49 148 − 12 284
(32,16) PrivSet 1 22 485 227 1 218 502 1 12 624 1 1 879 1 531
TDC_CLDP 24 7 363 333 24 73 633 23 4 597 22 731 20 179
BRR − 184 319 994 − 1 843 194 − 115 194 − 18 426 − 4 602
(64,8) PrivSet 4 25 296 086 4 248 035 3 14 606 2 2 007 1 359
TDC_CLDP 36 11 202 249 35 112 011 33 6 984 29 1 103 23 263
BRR − 819 199 993 − 8 191 993 − 511 993 − 81 913 − 20 473
(64,16) PrivSet 2 48 925 531 2 477 949 2 28 134 1 3 852 1 791
TDC_CLDP 40 12 482 015 39 124 817 38 7 788 34 1 234 29 298
BRR − 3 932 159 992 − 39 321 592 − 2 457 592 − 393 208 − 98 296
(64,32) PrivSet 1 90 897 749 1 883 327 1 51 057 1 7 619 1 2 167
TDC_CLDP 48 15 041 666 48 150 416 46 9 391 44 1 493 40 365
BRR − 1 474 559 988 − 14 745 588 − 921 588 − 147 444 − 36 852
(128,16) PrivSet 4 103 015 973 4 1 009 489 3 59 292 2 8 128 1 1461
TDC_CLDP 72 22 721 165 71 227 184 66 14 166 58 2 238 46 535
从表 3 中可以发现:
(1) (d,m)的值相同时,随着隐私参数(ε为 PrivSet 与 BRR 的参数,α为 TDC_CLDP 的参数)的增长,错误边界
都是下降的,符合理论推断.因为随着隐私参数的增长,隐私性越来越低,而效用性会越来越高,错误边
界也会越来越小.
(2) 从 k 值的角度来看:一方面 TDC_CLDP 与 PrivSet 两种方法的 k 值均会随着隐私参数的增长而减小,
原因是噪声项越来越少;另一方面,PrivSet 的 k 值非常小,最终随着隐私参数的增长会变成 1.这是因为
PrivSet 方法主要用于单个项的支持度计数估计,相当于 1-频繁项集的支持度计数估计,因此 k 值为 1
是符合理论的;而 TDC_CLDP 的 k 值一般会比较大,这是因为 TDC_CLDP 方法为了满足频繁项集挖
掘任务,采用了不同的距离度量函数,保留了更多的信息.