
Page 241 - 《软件学报》2021年第10期
P. 241
朱阅岸 等:构建新型高性能与高可用的键值数据库系统 3213
题,使得 LogBase 只写一次日志.
我们将修改后的 LogBase 发布在 github,https://github.com/logkv/logbase_changed 上.
LogStore 采用 C++实现,大约 1 万行代码.对于内存索引,系统使用 ART Tree.所有读操作将首先检查缓冲区.
如果没有找到,则通过索引确定数据在文件中的位置.数据复制功能嵌入到 LogStore 中,因此,我们可以细致地评
估日志即数据的设计理念带来的好处.在实验中,使用 HBase(版本 2.1.0)和 HDFS(版本 3.1.1).HBase 配置的内存
缓存为 8GB.对于 HDFS,所有设置都保持默认,特别是块大小为 64MB,复制因子为 3.实验中使用的数据由 YCSB
9
生成.数据记录的大小约 1KB,key 的范围是(0,210 ).我们在每次实验前预热系统.
3.2 基准测试
3.2.1 写性能
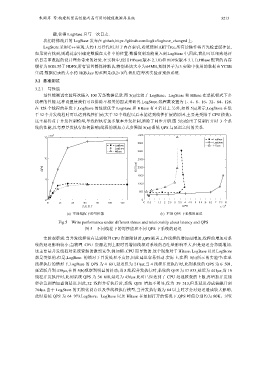
写性能测试实验每次插入 100 万条数据记录.图 5(a)比较了 LogBase、LogStore 和 HBase 在单机模式下多
线程的性能.这种设置使我们可以排除不相关的因素来研究 LogStore.线程数设置为 1、4、8、16、32、64、128.
在 128 个线程的并发下,LogStore 的性能优于 LogBase 和 HBase 有 4 倍以上.另外,如图 5(a)所示,LogStore 在低
于 32 个并发线程时可以达到线性扩展(大于 32 个线程以后未能达到线性扩展的原因,主要是受限于 CPU 核数).
这主要得益于并发控制模型,单线程执行加多版本并发控制,消除了同步开销.图 5(b)给出了复制打开时 3 个系
统的性能,以考察并发执行如何影响(线程的增加方式参照图 5(a))系统 QPS 与延迟之间的关系.
(a) 不同线程下的写性能 (b) 不同 QPS 下系统的延迟
Fig.5 Write performance under different threas and relationship about latency and QPS
图 5 不同线程下的写性能和不同 QPS 下系统的延迟
实验观察到:当并发线程没有达到物理 CPU 资源限制时,QPS 随着工作线程的增加而增加,线程的增加对系
统的延迟影响较小;当物理 CPU 资源达到上限时再增加线程对系统的吞吐量影响不大,但是延迟会急剧增加.
这主要是并发线程对系统资源的激烈竞争,例如锁、CPU 而导致的.这个现象对于 HBase、LogBase 以及 LogStore
都是类似的.但是,LogBase 的锁对于并发处理不友好,因此延迟容易抖动.实际上,在图 5(b)所示的实验中:在单
线程执行的情形下,LogBase 的 QPS 为 4 691,延迟仅为 211s;当 4 线程并发执行时,此刻系统的 QPS 为 6 501,
延迟跃升到 430s,在图 5(b)观察到明显的抖动;当 8 线程并发执行时,系统的 QPS 为 17 833,延迟为 441s;当 16
线程并发执行时,此刻系统 QPS 为 34 618,延迟为 436s.此时已经达到了 CPU 处理核数的上限,再增加并发线
程会急剧增加查询延迟.因此,32 线程并行执行时,系统 QPS 增加不明显,仅为 39 513,但是延迟却成倍飙升到
764s.由于 LogStore 的无锁化设计以及单线程执行模型,当并发执行数为 64 以上时才会对延迟造成较大影响,
此时系统 QPS 为 64 973.LogStore、LogBase 以及 HBase 在复制打开的情况下,QPS 峰值分别约为 80K、37K