
Page 238 - 《软件学报》2021年第10期
P. 238
3210 Journal of Software 软件学报 Vol.32, No.10, October 2021
2) replayed_lsn<l≤potential_commit_lsn:如果读请求的时间戳落入此区间,那么该请求需要被阻塞直到
备机收到主机推送的提交位点,然后回放完成;
3) l>potential_commit_lsn 或 l≥flushed_lsn:这种情况下,该请求需要被丢弃.
在单拷贝系统下,可以对第 2 种情况进行优化.系统只需将 replayed_lsn 推进到 potential_commit_lsn,表示此
区间日志已经回放完成,并且可以为查询提供服务,这几乎完全消除了图 3(b)所示的主从差距.当读取请求从元
服务器获取最新的读取视图位点 l 后向备机请求数据,它可以将 potential_commit_lsn 与 l 进行比较.若 l 不大于
potential_commit_lsn,则读取请求可以利用内存中的索引来检索数据,而无需等待回放操作,提高了备机的可见
性与数据库的响应速度.
2.3.2 复制技术
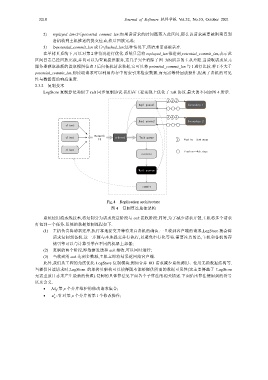
LogStore 复制算法类似于 raft 同步复制协议.我们在工程实现上优化了 raft 协议.最大的不同如图 4 所示.
Repl queue1 Secondary 1
Repl queue2 Secondary 2
client
Network
client ordered Task queue
IO Pipeline---Send stage
client
Pipeline---Ack stage
execute
Wait quorum
commit
Fig.4 Replication architecture
图 4 复制算法总体架构
系统使用流水线技术,将复制分为请求发送阶段与 ack 接收阶段;同时,为了减少请求开销,主机将多个请求
打包到一个任务.系统的数据复制流程如下.
(1) 主机负责将请求定序,执行本地提交并等待来自备机的确认.一旦收到客户端的请求,LogStore 就会将
请求复制到备机.这一步骤与本地提交并行执行,以避免串行化等待.需要注意的是,主机和备机的存
储引擎可以与计算引擎在不同的机器上部署;
(2) 复制的两个阶段,即数据发送和 ack 接收,可以同时进行;
(3) 当收到的 ack 达到多数派,主机立即将结果返回给客户端.
此外,我们从工程的角度优化 LogStore 复制模块,例如合并 I/O 请求减少系统调用、使用无锁数据结构等.
当提供只读请求时,LogStore 的单拷贝架构可以使得副本能够提供所需的数据可见性(这主要得益于 LogStore
无需重放日志来产生最新的快照).复制的具体算法见下面各个子算法的相关描述.下面给出算法使用到的符号
以及含义.
p :第 p 个分片维护的修改请求集合;
u i p :针对第 p 个分片的第 i 个修改操作;