
Page 175 - 《软件学报》2021年第10期
P. 175
郭军军 等:融入案件辅助句的低频和易混淆罪名预测 3147
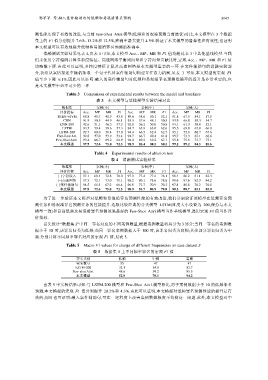
测性能实现了有效的改进.与当前 Few-Shot Attri.模型(低频和易混淆预测当前最优)对比,本文模型在 3 个数据
集上的 F1 值分别提升 7.6%、13.2%和 12.5%,准确率最大提升 4.5%.验证了本文模型的鲁棒性和有效性,也证明
本文模型可以有效地提升低频和易混淆罪名预测的准确率.
消融测试实验结果见表 4,由表 4 可知,本文模型 Acc.、MP、MR 和 F1 值均超过表 3 中其他基线模型.当我
们未使用字符编码计算多粒度特征、高速网络平衡词向量和字符向量贡献比时,宏观 Acc.、MP、MR 和 F1 值
均略微下降.由此可以证明,多粒度特征计算及高速网络是本文模型重要的一环.在案件辅助句的消融实验部
分,我们从案情描述中随机抽取一个句子代替案件辅助句构建互注意力机制.从表 3 可知,本文模型的宏观 F1
值至少下降 6.1%.因此可以证明:融入的案件辅助句对低频和易混淆罪名预测准确率的提升是非常重要的,也
是本文模型中必不可少的一环.
Table 3 Comparison of experimental results between the model and baselines
表 3 本文模型与基线模型实验结果对比
数据集 案例(小) 案例(中) 案例(大)
评价指标 Acc. MP MR F1 Acc. MP MR F1 Acc. MP MR F1
TRIDF+SVM 85.8 49.7 41.9 43.5 89.6 58.8 50.1 52.1 91.8 67.5 54.1 57.5
CNN 91.9 50.5 44.9 46.1 93.5 57.6 48.1 50.5 93.9 66.0 50.3 54.7
CNN-200 92.6 51.1 46.3 47.3 92.8 56.2 50.0 50.8 94.1 61.9 50.0 53.1
LSTM 93.5 59.4 58.6 57.3 94.7 65.8 63.0 62.6 95.5 69.8 67.0 66.8
LSTM-200 92.7 60.0 58.4 57.0 94.4 66.5 62.4 62.7 95.1 72.8 66.7 67.6
Fact-Law Att. 92.8 57.0 53.9 53.4 94.7 66.7 60.4 61.8 95.7 73.3 67.1 68.6
Few-Shot Attri. 93.4 66.7 69.2 64.9 94.4 69.2 69.2 67.1 95.8 75.8 73.7 73.1
本文模型 97.9 72.6 75.0 72.5 98.9 82.4 80.5 80.3 99.2 89.2 84.5 85.6
Table 4 Experimental results of ablation test
表 4 消融测试实验结果
数据集 案例(小) 案例(中) 案例(大)
评价指标 Acc. MP MR F1 Acc. MP MR F1 Acc. MP MR F1
()字符嵌入 97.1 69.3 72.8 70.0 97.9 77.4 77.6 76.1 98.3 86.2 81.1 82.3
()高速网络 97.3 72.1 73.0 71.1 98.2 80.1 78.6 78.8 98.6 87.6 82.9 84.2
()案件辅助句 94.5 66.3 67.2 66.4 96.8 72.7 70.9 70.2 97.8 80.8 78.2 78.6
本文模型 97.9 72.6 75.0 72.5 98.9 81.7 80.9 79.8 99.2 88.7 85.1 85.9
为了进一步验证本文模型对低频和易混淆罪名预测性能的有效改进,我们分别验证该模型在低频罪名预
测任务和易混淆罪名预测任务的性能提升.选取比较经典的分类模型 LSTM(维度大小设置为 200,保持与本文
模型一致)和目前低频及易混淆罪名预测效果最好的 Few-Shot Attri.模型当作基线模型,选用宏观 F1 值当作评
价指标.
首先统计“数据集 S”中同一罪名对应的不同案例数量,根据案例数量将其分为 3 部分:当同一罪名的案例数
据小于 10 时,该罪名归类为低频;当同一罪名案例数据大于 100 时,该罪名归类为高频;其余部分罪名归类为中
频.分别计算不同频率罪名对应的宏观 F1 值,见表 5.
Table 5 Macro F1 values for charge of different frequencies on case dataset S
表 5 数据集 S 上不同频率罪名的宏观 F1 值
罪名类别 低频 中频 高频
罪名数量 55 47 47
LSTM-200 32.1 54.5 82.7
Few-shot Attri. 48.6 59.2 85.5
本文模型 52.9 70.1 94.2
由表 5 中实验结果可知:与 LSTM-200 模型和 Few-Shot Attri.模型相比,对于案例数据小于 10 的低频罪名
预测,本文模型的宏观 F1 值分别提升 20.2%和 4.3%.由此可以证明,本文模型对低频罪名预测性能的提升是有
效的;同时也可证明:融入案件辅助句,可在一定程度上改善案例数据极度不均衡这一问题.此外,本文模型对中