
Page 323 - 《软件学报》2021年第9期
P. 323
田卓 等:神威太湖之光上分子动力学模拟的性能优化 2947
升性能,使得向量长度对齐、连续、大小规整.
本文第 1 节对神威太湖之光的结构及实例的计算模式进行描述.第 2 节给出神威上的几种优化技术,并进
行详细阐述.第 3 节对实现结果进行描述.第 4 节对已有研究工作进行分析和总结.第 5 节总结全文.
1 神威结构及计算实例
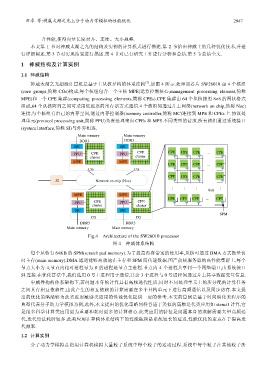
1.1 神威结构
[7]
神威太湖之光超级计算机是基于主从核异构的体系结构 ,如图 4 所示.处理器芯片 SW26010 由 4 个核组
(core groups,简称 CGs)构成,每个核组包含一个主核 MPE(运算控制核心,management processing element,简称
MPE)和一个 CPE 集群(computing processing elements,简称 CPEs).CPE 集群由 64 个从核按照 8×8 的网状格式
组成,64 个从核阵列之间可采用低延迟的寄存器方式通信.4 个核组间通过片上网络(network on chip,简称 Noc)
连接,每个核组有自己的内存空间,通过内存控制器(memory controller,简称 MC)连接到 MPE 和 CPEs 上.协议处
理单元(protocol processing unit,简称 PPU)负责处理来自 CPEs 和 MPE 不同类型的请求.所有核组通过系统接口
(system interface,简称 SI)与外界相连.
Main memory Main memory
DDR3 DDR3
MC MC
PPU CPE PPU CPE CPE CPE CPE ... CPE
cluster cluster
MPE MPE
CPE CPE CPE ... CPE
CG CG
CPE CPE CPE CPE
SI Network on chip (Noc)
... ... ... 8x8 ...
MPE MPE
CPE CPE CPE ... CPE
PPU CPE PPU CPE
cluster cluster
MC MC
SPM
CG CG
DDR3 DDR3
Main memory Main memory
Fig.4 Architecture of the SW26010 processor
图 4 神威体系结构
每个从核有 64KB 的 SPM(scratch pad memory).为了提高内存带宽的使用率,从核可通过 DMA 方式批量访
问主存(main memory),DMA 通道能够高效地在主存和 SPM 间传递数据.国产众核服务器的高性能集群上,每个
节点大小为 4,节点内相对进程号为 0 的进程是节点主进程.节点内 4 个进程共享同一个网络端口,由系统接口
SI 连接.在优化算法中,我们选用 0 号主进程用于通信,其余 3 个进程与 0 号进程间通过片上共享数据交互信息.
申威异构的体系架构下,若问题本身的计算具有高频迭代性质,同时不同处理单元上的所分配的计算任务
之间具有相互依赖性,由此产生的相互依赖的计算需要在多个异构单元下进行高频通信以及同步访存.本文提
出的优化策略能够为此类延迟敏感类应用的性能优化提供一定的参考.本文的算例是基于时间演化类程序的
典型代表分子动力学模拟为例,此外,本文提出的优化策略同样普适于类似的高频迭代类应用如 stencil 计算,它
是很多科学计算类应用最为重要和耗时最多的计算核心.此类应用的特征是问题本身的求解需要大量高频迭
代,迭代算法耗时较多.此类应用在异构体系结构下的性能瓶颈是系统较长的延迟,性能优化的重点在于提高迭
代频率.
1.2 计算实例
分子动力学模拟是指用计算机模拟大量粒子系统中每个粒子的运动过程.系统中每个粒子在其他粒子所