
Page 54 - 《软件学报》2021年第8期
P. 54
2336 Journal of Software 软件学报 Vol.32, No.8, August 2021
访问速率.然而,锁页内存一般为连续的物理内存空间,其申请受到单一 NUMA 节点上内存大小的限制.为确
保数据在 Host 端及 Device 端对应,在拥有若干协处理平台上,单次申请的锁页内存容量很可能远小于所有设
备内存的总和 [10] .因此,面向 Hetero-HPL,我们对原始矩阵建立软件缓存,采用若干锁页内存来替代非锁页
内存.
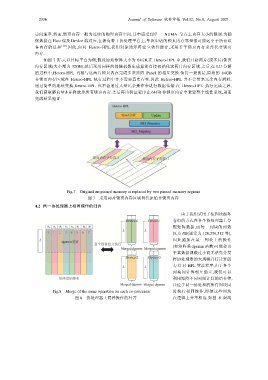
如图 7 所示,以目标平台为例,假设原始矩阵大小为 64GB,在 Hetero-HPL 中,我们开辟两片(或多片)锁页
内存区域(大小都为 32GB),然后采用同样的伪随机数生成算法直接初始化这两片内存区域.之后,在 LU 分解
的过程中,Hetero-HPL 直接与这两片锁页内存完成多次矩阵 Panel 的相互交换.值得一提的是,原始的 64GB
非锁页内存区域在 Hetero-HPL 执行过程中并不需要真实存在,因此 Hetero-HPL 并不会带来冗余内存消耗.
通过简单的地址变换,Hetero-HPL 也不会通过大量冗余操作来进行数据传输.在 Hetero-HPL 执行完成之后,
我们获取解向量 b 并释放掉所有锁页内存.之后再由验证程序在 64GB 非锁页内存中重建整个线性系统,进而
完成结果验证.
Fig.7 Original un-pinned memory is replaced by two pinned memory regions
图 7 采用两片锁页内存区域替代原始非锁页内存
4.2 同一协处理器上相同操作的归并
由于我们采用了按列块循环
卷帘的方式在各个协处理器上分
配矩阵数据,而每一列块的列数
仅为 NB(通常为 128,256,512 等),
因此施加在某一列块上的操作
(如矩阵乘 dgemm 函数)可能会由
于其数据规模过小而无法充分发
挥协处理器的大规模并行计算能
力.针对 HPL 算法程序,由于各个
列块间计算相互独立,我们可以
利用矩阵不同列间计算的结合律,
让位于同一协处理的所有列块同
Fig.8 Merge of the same operation on each co-processor 时执行相同操作,即便这些列块
图 8 协处理器上同种操作的归并 在逻辑上并不相连.如图 8 虚线