
Page 56 - 《软件学报》2021年第8期
P. 56
2338 Journal of Software 软件学报 Vol.32, No.8, August 2021
Fig.9 Efficiency trend of single process Hetero-HPL with respect to matrix rank
图 9 单进程 Hetero-HPL 执行效率随着矩阵阶数变化趋势
5.3 多节点实验结果
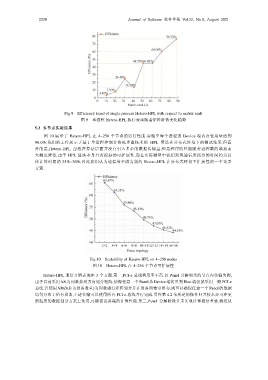
图 10 展示了 Hetero-HPL 在 4~256 个节点的运行性能.实验中每个进程的 Device 端内存使用量达到
96.0%.我们的工作展示了基于单进程控制多协处理器技术的 HPL 算法在分布式环境下的测试结果.但意
外的是,Hetero-HPL 虽然在算法层面并没有引入多余的数据传输量,但是程序的性能随着进程数的增加而
大幅度降低.由于 HPL 算法本身具有很好的可扩展性,而在实际测量中我们发现通信所耗费的时间约为总
体计算时间的 25%~30%,因此我们认为通信效率成为制约 Hetero-HPL 在分布式环境下扩展性的一个重要
方面.
Fig.10 Scalability of Hetero-HPL on 4~256 nodes
图 10 Hetero-HPL 在 4~256 个节点可扩展性
Hetero-HPL 通信开销表现在 3 个方面.第一,PCI-e 总线利用率不高.以 Panel 分解相关的节点内传输为例,
由于目前采用 NB 为列数按列方向划分矩阵,使得任意一个 Panel 从 Device 端拷贝到 Host 端仅能采用一路 PCI-e
总线.若使用 NB/D(D 为设备数量)为列数进行矩阵划分并在设备间卷帘排布,则可以确保任意一个 Panel 的数据
均匀分布于所有设备,上述传输可以使用所有 PCI-e 总线并行完成.另外第 4.2 节所述的操作归并技术亦可在更
细粒度的数据划分方案上使用,可确保设备端的计算性能.第二,Panel 分解阶段并未实现计算通信重叠.我们认