
Page 49 - 《软件学报》2021年第8期
P. 49
孙乔 等:面向异构计算机平台的 HPL 方案 2331
利用各种硬件资源.
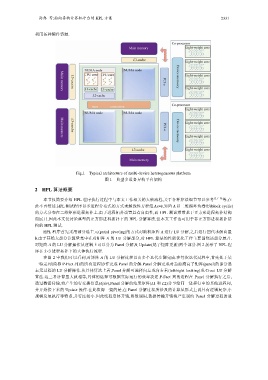
Fig.1 Typical architecture of multi-device heterogeneous platform
图 1 典型多设备异构平台架构
2 HPL 算法概要
本节仅简要介绍 HPL 程序执行过程中与本文工作相关的大致流程,关于各种算法细节可以参考 [3,7−9] 等,在
此不再赘述.HPL 测试程序以多进程分布式的方式求解线性方程组 Ax=b.矩阵 A 以二维循环块卷帘(block cyclic)
的方式分布在二维矩形进程拓扑上.由于进程拓扑设置具有自由性,而 HPL 测试常常基于正方形进程拓扑结构
而展开,因此本文仅讨论典型的正方形进程拓扑下的 HPL 分解算法,但本文工作也可用于非正方形进程拓扑结
构的 HPL 测试.
HPL 程序首先采用部分选主元(patial pivoting)的方式对随机矩阵 A 进行 LU 分解,之后进行回代求解向量
b.由于其绝大部分计算量集中在对矩阵 A 的 LU 分解部分,对 HPL 算法的性能优化工作主要围绕该部分展开.
对矩阵 A 的 LU 分解操作从逻辑上可以分为 Panel 分解及 Update(尾子矩阵更新)两个部分.图 2 展示了 HPL 程
序在 3×3 进程拓扑下的大体执行流程.
在图 2 中我们可以看到,对矩阵 A 的 LU 分解过程以由多个迭代步骤完成.在每次迭代过程中,首先处于某
一特定列(简称 P-Fact 列)的所有进程协作完成 Panel 的分解.Panel 分解完成对当前瘦高子矩阵(panel)的部分选
主元过程的 LU 分解操作.从具体算法上看,Panel 分解可选择向左或向右看(left/right looking)或 Crout LU 分解
算法.这三者计算量大致相等,具体的选择可根据实际运行的效率决定.P-Fact 列的进程在 Panel 分解执行之后,
通过数据传输,将产生的行交换信息(dpiv),Panel 分解的结果矩阵(L1 和 L2)分享给同一进程行中的其他进程列,
并开始接下来的 Update 操作.在此值得一提的是,在 Panel 分解过程所涉及的计算从形式上说具有逻辑复杂,小
规模反复执行等特点,并行度较小.因此线程启停开销,函数调用,数据传输开销将严重制约 Panel 分解过程的效