
Page 250 - 《软件学报》2021年第8期
P. 250
2532 Journal of Software 软件学报 Vol.32, No.8, August 2021
人 [84] 研究了对抗性规则化的优缺点,其可能产生不稳定的梯度和在域内示例上的性能急剧下降.在训练过程中
逐步引入正则化,有助于减轻这些问题.AdvReg 提高了对二元问题的泛化能力,但降低了对异质答案分布问题
的性能.正则化模型往往过度依赖视觉特征,而忽略了问题中重要的语言线索.Belinkov 等人 [85] 在自然语言推理
(natural language inference)任务上采用了相似的对抗策略,基准模型采用假设和前提来预测标签,而采用对抗策
略的模型加入了只采用假设的分类器,或者针对一个假设随机采用一个前提进行训练.但是在 Grand 等人 [84] 的
研究中显示:对抗性训练方法给梯度带来了很大的噪声,导致训练过程不稳定,可能导致性能的严重下降,引入
正规化有助于缓解但不能完全解决这些问题.
(2) 基于融合的方式
基于融合的方式是将两个分支预测答案的分布在最后进行融合,并基于融合的答案分布导出训练梯度.基
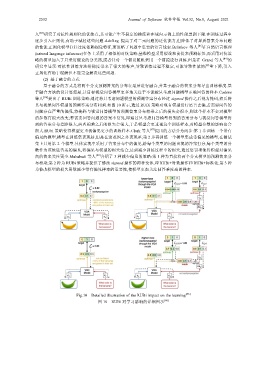
于融合方法的设计思想是,让目标视觉问答模型更多地关注于不能被只考虑问题模型正确回答的样本.Cadene
等人 [86] 提出了 RUBi 训练策略,通过将只考虑问题模型的预测答案分布经过 sigmod 操作之后视为掩码,然后将
其与视觉问答模型的预测答案分布相乘.如图 10 所示,通过 RUBi 策略对现有模型进行语言去偏,若需要问答的
问题存在严重的偏见,将掩码与视觉问答模型的预测答案分布相乘之后的损失会很小,则这个样本不会对模型
的参数有很大改变;若需要回答问题的答案不常见,即通过只考虑问答模型得到的答案分布与视觉问答模型得
到的答案分布差距很大,两者相乘之后的损失会很大,于是模型会更重视这个训练样本,对模型参数的影响也会
很大.RUbi 策略使得模型更重视偏见更小的训练样本.Clark 等人 [87] 提出的方法分为两步:第 1 步训练一个带有
偏见的模型,模型在训练集表现好,但是在这范围之外表现差;第 2 步再训练一个模型集成带偏见的模型,在测试
集上只用第 2 个模型.具体实现中采用了答案分布中的偏见,给每个类型的问题出现的答案打分,每个类型的分
数作为该候选答案的偏见,将偏见与模型的损失结合,达到减少训练过程中的损失,通过惩罚项使得模型对偏见
高的答案关注更少.Mahabadi 等人 [88] 介绍了 3 种减少偏见的策略:第 1 种为直接将两个分支模型的预测答案分
布相乘;第 2 种为 RUBi 策略并提供了修改 sigmod 操作的两种变体,即 RUBi+对数操作和 RUBi+标准化;第 3 种
为修改模型的损失函数减少带有偏见样本的重要性,使模型更加关注回答难度高的样本.
Fig.10 Detailed illustration of the RUBi impact on the learning [86]
图 10 RUBi 对学习影响的详细图示 [86]