
Page 316 - 《软件学报》2021年第7期
P. 316
2234 Journal of Software 软件学报 Vol.32, No.7, July 2021
和 8.3%,说明通过调节权重比例系数,可以改变语言模型对有/无缺陷软件模块学习的抑制/增强程度,进而可
以有效提升 CE 类度量元的缺陷预测性能.
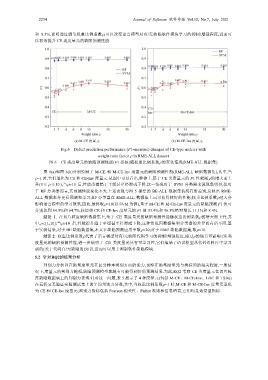
(a) M-CE 度量元 (b) M-CE-Inv 度量元
Fig.6 Defect prediction performance (F1-measure) changes of CE-type metrics with
weight ratio factor in RME-ALL dataset
图 6 CE 类度量元的缺陷预测性能(F1 指标)随权重比例系数的变化情况(RME-ALL 数据集)
图 6(a)和图 6(b)分别绘制了 M-CE 和 M-CE-Inv 度量元的缺陷预测性能(RME-ALL 缺陷数据集),其中,当
=1 时,它们退化为 CE 和 CE-Inv 度量元.从图中可以看出,整体上,基于 CE 类度量元的 F1 性能随的增大而上
升(1≤≤ 10 ),当10 后,性能改善趋于平缓甚至停滞或下降.这一情况对于 SVM 分类器来说现象明显,但对
于 RF 分类器而言,其预测性能变化不大.上述表现与图 5 描绘的 BE-ALL 数据集情况有所差别,反映出 RME-
ALL 数据本身更易预测和学习;RF 分类器在 RME-ALL 数据集上已可获得较好的性能;权重比例系数过大会
影响语言模型的学习效果.因此,最终取=10(以 SVM 为例),基于 M-CE 和 M-CE-Inv 度量元的缺陷预测 F1 值可
分别达到 64.5%和 64.7%,较原始 CE 和 CE-Inv 度量元的 F1 值 53.4%和 56.3%绝对增长 11.1%和 8.4%.
结论 1. 在切片粒度缺陷数据集上,基于 CE 类度量元的缺陷预测性能随权重比例系数的增大而上升,其
中,[1,10];当10 后,性能提升趋于平缓甚至停滞或下降,这种情况因数据集和分类器的差异而有所不同.基
于实验结果,对于 BE 缺陷数据集,本文在缺陷预测应用中取=20;对于 RME 缺陷数据集,取=10.
结论 2. 权重比例系数代表了语言模型对有/无缺陷代码学习的抑制/增强程度,通过的调节可影响 CE 类
度量元的缺陷预测性能,进一步说明了 CE 类度量元具有可学习性,它们蕴涵了语言模型从代码语料库中学习
到的(关于代码有/无缺陷的)知识,进而可以用于判别软件缺陷模块.
5.2 针对RQ2的结果分析
判别力分析旨在衡量度量元在区分样本类别方面的能力,也即在衡量度量元与类标间的相关程度.一般情
况下,度量元的判别力越强,缺陷预测模型就越有可能得到好的预测结果.为此,RQ2 考察 CE 类度量元在切片粒
度缺陷数据集上的判别力表现.针对这一问题,表 5 展示了 4 种度量元(包括 M-CE、M-CE-Inv、LOC 和 TSize)
在五折交叉验证实验测试集上的平均判别力分数,其中,当权重比例系数=1 时,M-CE 和 M-CE-Inv 度量元退化
为 CE 和 CE-Inv 度量元;判别力指标包括 Pearson 相关性、Fisher 准则和信息增益,它们均是效益型指标.