
Page 315 - 《软件学报》2021年第7期
P. 315
张献 等:基于代码自然性的切片粒度缺陷预测方法 2233
在表 4 中,表示权重比例系数,其代表了语言模型对有/无缺陷代码学习的抑制/增强程度.当=1 时,不同质
量类型的样本权重相同,本质上,W-NLM 已退化为非加权的语言模型.从整体上看,模型在测试集上的 PP 值与训
练集的结果接近,说明模型的泛化性能良好;模型在 RME-ALL 数据集上的指标值比 BE-ALL 更低,说明前者数
据较后者更易学习;权重比例系数的增大会影响测试集 PP 值,这是由于模型降低了对有缺陷代码的学习权重;
逆向语言模型的 PP 值与正向语言模型得分接近,说明软件代码亦可进行逆序学习.
本文所提 CNDePor 方法的阶段 II(交叉熵度量阶段)是基于训练过的语言模型进行软件模块的熵值度量.
最后在第 III 阶段的缺陷预测应用中,将 CE 类度量元与传统度量元相融合,一同训练分类器并实现对软件模块
有/无缺陷倾向性的判别.下面依据上一节提出的研究问题,按序从 4 个方面进行实验与结果分析.
5.1 针对RQ1的结果分析
为提高软件缺陷预测性能,本文提出的 CNDePor 方法使用了新颖的双向语言模型 W-NLM 对代码进行度
量.其中,W-NLM 可以有效地利用软件模块的质量类型信息(即有/无缺陷的标签信息)对样本进行加权,进而提
高学习的针对性.经过加权学习后,语言模型将更倾向于赋予有/无缺陷模块更高/低的 CE 值,则得到的代码 CE
类度量元可更有效地完成缺陷预测.在 W-NLM 中,权重比例系数是一个十分关键的参数,它代表了语言模型对
有/无缺陷代码学习的抑制/增强程度.当=1 时,本质上 W-NLM 已退化为 NLM 模型,同时模型生成的 M-CE 和
M-CE- Inv 度量元退化为 CE 和 CE-Inv 度量元.
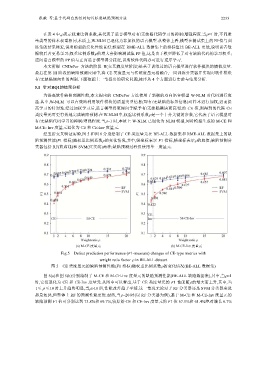
经五折交叉验证实验,图 5 和图 6 分别绘制了 CE 类度量元在 BE-ALL 数据集和 RME-ALL 数据集上的缺
陷预测性能(F1 指标)随权重比例系数的变化情况,其中,纵坐标表示 F1 指标,横坐标表示的取值;缺陷预测分
类器包括 RF(蓝虚线)和 SVM(红实线)两种;缺陷预测过程仅使用单一度量元.
(a) M-CE 度量元 (b) M-CE-Inv 度量元
Fig.5 Defect prediction performance (F1-measure) changes of CE-type metrics with
weight ratio factor in BE-ALL dataset
图 5 CE 类度量元的缺陷预测性能(F1 指标)随权重比例系数的变化情况(BE-ALL 数据集)
图 5(a)和图 5(b)分别绘制了 M-CE 和 M-CE-Inv 度量元的缺陷预测性能(BE-ALL 缺陷数据集),其中,当=1
时,它们退化为 CE 和 CE-Inv 度量元.从图中可以看出,基于 CE 类度量元的 F1 性能随的增大而上升,其中,当
1≤ ≤ 10 时上升趋势明显,当10 后,性能改善趋于平缓.这一情况无论对于 RF 分类器还是 SVM 分类器来说
都是如此,但整体上 RF 的预测性能更优.最终,当=20 时(以 RF 分类器为例),基于 M-CE 和 M-CE-Inv 度量元的
缺陷预测 F1 值可分别达到 73.8%和 69.7%,较原始 CE 和 CE-Inv 度量元的 F1 值 67.1%和 61.4%绝对增长 6.7%