
Page 190 - 《软件学报》2021年第5期
P. 190
1414 Journal of Software 软件学报 Vol.32, No.5, May 2021
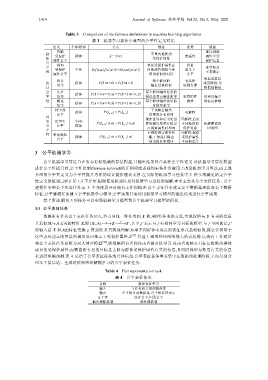
Table 3 Comparison of the fairness definitions in machine learning algorithms
表 3 机器学习算法中典型的公平性定义对比
定义 个体/群体 公式 描述 优势 挑战
忽略 难以剔除
感 受保护 群体 y ˆ = f () x 不显式地使用 普适性 属性中受
知 属性公平 受保护属性 保护信息
公 感知 包括受保护属性在 度量
平 度量距离
性 受保护 个体 D(f (x,a),f (x′,a′))≤d((x,a),(x′,a′)) 内的属性相似个体 意义下 不易确定
属性公平 得到相似的对待 公平
易造成算法
统计 每个群体的 有法律
统 均等 群体 P ˆ (| = ya 0) = P ˆ (| = y a 1) 输出结果相似 原则支撑 效用降低;导
计 致惰性做法
公 几率 群体 ˆ ( P y = 1| = a 0, ) = y ˆ ( P y = 1| = a 1, ) y 每个群体输出结果的
平 均等 错误率和正确率相等 惩罚惰性 易受带偏差
性 测试 群体 ( P y = 1| = a 0, ˆ) = y ( P y = 1| = a 1, ˆ) y 每个群体输出结果的 做法 的标记影响
均等 置信度相等
纯干预 群体 ˆ ( P y 0 ) = ˆ ( P y 1 ) 干预前后输出 可解释
公平 a = a = 结果的分布相同
因 现实世界和反事实世 可解释;适用
果 反事实 个体/ ˆ ( P y 0 |, ) =xa ˆ ( P y 1 | , )xa 界的输出结果在给定 不同粒度的 依赖假设的
公 公平 群体 a = a = 可观察属性时相同 保护对象 因果图
平 干预沿指定路径传 可解释;保留
性 特定路径 群体 ˆ ( P y 0 |π = ˆ ( P y 1 | ) π 播,干预前后输出 受保护属性
)
公平 a = a =
结果的分布相同 本身的差异
3 公平机器学习
公平机器学习算法旨在发布近似准确的算法模型,且输出结果符合某种公平性定义.对机器学习算法模型
进行公平性提升时,公平性定制(fairness-tailored)的正则项或者强约束条件常被用于改进机器学习算法,而上述
介绍的公平性定义为公平性提升方法的设计提供理论支撑.在实际的机器学习任务中,3 种实现满足给定公平
性定义的机制已经在第 1.3 节介绍.根据使用机制以及对机器学习过程的理解,本文主要从公平表征任务、公平
建模任务和公平决策任务这 3 个角度展开对现有工作的梳理:公平表征任务建立公平数据集或提取公平数据
特征;公平建模任务建立公平机器学习模型;公平决策任务使用机器学习模型的输出结果进行公平决策.
综上所述,解决 3 项任务可以实现机器学习模型到公平机器学习模型的衍化.
3.1 公平表征任务
数据所有者从公平表征任务切入,努力寻找一种作用到 X 和A的特征变换方法,实现保留与 Y 有关的信息
且近似地与A无关的特征 Z,即 (, ) ⎯⎯→AX g ⎯Z ⎯ f ′ →Y ,其中,f ′表示与 f 有相同学习目标的模型.与 f 不同的是,f ′
的输入是 X 和A由特征变换 g 得到的 Z.直观地理解:如果不同群体中成员的表征形式是相似的,那么任何基于
这些表征建立的算法所做决策应独立于受保护属性A [23] .得益于深度神经网络强大的表达能力,现有工作通常
将公平表征任务建模为双人博弈模型 [34] ,即数据所有者和攻击者做对抗学习.攻击者的核心目标是推断出群体
成员的受保护属性;而数据所有者的目标是去除与群体受保护属性有关的信息,且同时保留与效用有关的信息
来进行准确预测.表 4 总结了公平表征任务的具体信息.公平表征任务重点集中在数据预处理阶段,下面分别介
绍基于信息论、生成对抗网络和解耦学习的公平表征任务.
Table 4 Fair representation task
表 4 公平表征任务
目标 数据表征学习
输入 与任务相关的训练样本
输出 公平的合成数据集,公平的特征表示
公平性 统计公平,因果公平
偏差消除机制 预处理机制